3+5=8 10+7=17 7-3=4 4*4=16 8*9=72
3*98=294 3^4=81 5^3=125 10%100=10 15%900=135
135 in octal=207 243 in hex=f3 385 in binari=10110011
6+4+9=19 30+46+70=146 (9+10)*3=270 year in days=365
20 km a m=20000
sábado, 28 de noviembre de 2009
MENUS OCULTOS DEL SISTEMA OPERATIVO WINDOWS
Menús ocultos del sistema operativo Windows XP
Además de las numerosas opciones de configuración que incluye Windows XP en el Panel de Control, existen otras opciones adicionales que sólo son accesibles a través de ciertos comandos.
El sistema operativo Microsoft Windows XP incluye muchas funciones a las que tan sólo podemos acceder a través de la consola de comandos. A menudo estas herramientas nos pueden ayudar a mejorar el rendimiento de nuestro sistema operativo, diagnosticar y corregir problemas o simplemente obtener más información sobre la configuración de nuestro equipo.
Para acceder a la consola de comandos, tan sólo tendremos que ir al menú Inicio, seleccionar la opción ejecutar y escribir cmd.exe ó simplemente cmd. También podremos acceder a este menú mediante la combinación del teclado tecla Windows+R.
Para obtener ayuda adicional sobre un comando, las opciones que incluye y algunos ejemplos de uso, tan sólo tendremos que añadirle la opción /h ó /?.
Archivos y sistemas de ficheros
cacls: Permite modificar los permisos en ficheros y carpetas, permitiendo o prohibiendo a cada usuario leer, escribir o modificar el contenido de dichos archivos o carpetas.
chkdsk: Comprueba el estado de una partición y repara los daños en caso de que encuentre alguno. Si lo ponemos sin ningún parámetro simplemente escaneará la partición, si queremos que además corrija los errores, deberemos añadir la opción /F, es decir, chkdsk /F.
cipher: Permite cifrar archivos, directorios o particiones siempre que se encuentren en el sistema de archivos NTFS.
comp: Compara archivos o carpetas y muestra las diferencias existentes entre ellos.
compact: Permite comprimir archivos o carpetas para ahorrar espacio en el disco duro. Para comprimir los archivos deberemos utilizar el modificador /c y para descomprimirlo en modificador /u. Por ejemplo, para comprimir la carpeta c:\pruebas debemos utilizar el comando compact /c c:\pruebas y para descomprimirla compact /u c:\pruebas.
convert: Convierte particiones FAT ó FAT32 a NTFS. Antes de utilizar este comando es recomendable realizar una copia de seguridad puesto que es posible que durante la conversión se pierdan datos.
defrag: Desfragmenta los archivos de una unidad, similar a la utilidad Defragmentador de discos de Windows pero en modo consola.
diskpart: Permite crear, eliminar y administrar particiones. Este programa en modo consola debemos utilizarlo con cuidado puesto que es fácil que eliminemos sin darnos cuenta todo el contenido del disco duro o de la partición activa.
find y findstr: Estos comandos buscan cadenas de textos en el interior de uno o varios archivos. Sin embargo, el comando findstr ofrece más opciones de búsqueda que el comando find.
iexpress: Este comando lanzará un asistente para crear archivos comprimidos .CAB autodescomprimibles.
openfiles: Muestra a un administrador los archivos abiertos en un sistema a un administrador y permite desconectarlos si se han abierto a través de red.
Configuración del sistema
bootcfg: Permite ver y modificar las entradas del archivo boot.ini. Estas entradas nos permiten seleccionar con que sistema operativo deseamos iniciar el equipo.
control userpasswords2: Permite modificar las claves y los permisos de los diferentes usuarios, así como requerir la pulsación de control+alt+suprimir para poder iniciar sesión, haciendo el inicio de sesión más seguro.
driverquery: Hace un listado de todos los drivers instalados en el sistema y muestra información sobre cada uno de ellos.
dxdiag: Lanza la herramienta de diagnóstico de Direct X, con la cual podremos comprobar la versión Direct X que tenemos instalada y permite comprobar mediante tests que todo lo referente a estos controladores funcione correctamente.
gpresult: Muestra información sobre las políticas de grupo aplicadas a un usuario.
gpupdate: Vuelve a aplicar las políticas de grupo.
msconfig: Desde esta aplicación en modo gráfico podremos seleccionar que programas y servicios se cargan durante el inicio de Windows así como los sistemas operativos que el usuario puede seleccionar para iniciar el ordenador.
pagefileconfig: Permite configurar el archivo de paginación de Windows.
prncnfg: Muestra información sobre las impresoras instaladas
prnjobs: Muestra información sobre los trabajos de impresión en cola.
reg: Permite ver y modificar valores del registro de Windows. Las opciones posibles son:
reg query => realiza una consulta en el registro
reg add => añade una entrada al registro
reg delete => elimina una clave del registro
reg copy => copia una clave del registro a otra parte del registro o a otro equipo
reg save => guarda una parte del registro en un archivo
reg restore => restaura una parte del registro de un archivo
reg load => carga una clave o árbol al registro desde un archivo
reg unload => descarga una clave o árbol del registro
reg compare => compara varios valores del registro
reg export => exporta el registro o parte del registro a un archivo
reg import => importa el registro o parte del registro de un archivo
regedit: Editor del registro en modo gráfico.
sc: Este commando nos permite administrar los servicios, ya sea iniciar uno, detenerlo, mandarle señales, etc.
sfc: Este comando permite buscar archivos del sistema dañados y recuperarlos en caso de que estén defectuosos (es necesario el CD de instalación del sistema operativo para utilizarlo). Para realizar una comprobación inmediata, deberemos ejecutar la orden sfc /scannow.
systeminfo: Muestra información sobre nuestro equipo y nuestro sistema operativo: número de procesadores, tipo de sistema, actualizaciones instaladas, etc.
taskkill: Permite eliminar un proceso conociendo su nombre o el número del proceso (PID).
tasklist: Realiza un listado de todos los procesos que hay. Útil si deseamos eliminar un proceso y no conocemos exactamente su nombre o su PID.
Redes
arp: Muestra y permite modificar las tablas del protocolo ARP, encargado de convertir las direcciones IP de cada ordenador en direcciones MAC (dirección física única de cada tarjeta de red).
ftp: Permite conectarse a otra máquina a través del protocolo FTP para transferir archivos.
getmac: Muestra las direcciones MAC de los adaptadores de red que tengamos instalados en el sistema.
ipconfig: Muestra y permite renovar la configuración de todos los interfaces de red.
nbtstat: Muestra las estadísticas y las conexiones actuales del protocolo NetBIOS sobre TCP/IP, los recursos compartidos y los recursos que son accesibles.
net: Permite administrar usuarios, carpetas compartidas, servicios, etc. Para un listado completo de todas las opciones, escribir net sin ningún argumento. Para obtener ayuda sobre alguna opción en concreto, escribier net help opción.
netsh: Este programa en modo consola permite ver, modificar y diagnosticar la configuración de la red
netstat: Mediante este comando obtendremos un listado de todas las conexiones de red que nuestra máquina ha realizado.
nslookup: Esta aplicación se conecta a nuestros servidores DNS para resolver la IP de cualquier nombre de host. Por ejemplo, si ejecutamos nslookup y escribimos www.hispazone.com, nos responderá con algo como:
Respuesta no autoritativa:
Nombre: www.hispazone.com
Address: 217.76.130.250
Esto quiere decir que la dirección web www.hispazone.com corresponde con la IP 217.76.130.250.
pathping: Muestra la ruta que sigue cada paquete para llegar a una IP determinada, el tiempo de respuesta de cada uno de los nodos por los que pasa y las estadísticas de cada uno de ellos.
ping: Poniendo detrás del comando ping el nombre o la dirección IP de la máquina, por ejemplo ping 192.168.0.1 enviaremos un paquete a la dirección que pongamos para comprobar que está encendida y en red. Además, informa del tiempo que tarda en contestar la máquina destino, lo que nos puede dar una idea de lo congestionada que esté la red.
rasdial: Permite establecer o finalizar una conexión telefónica.
route: Permite ver o modificar las tablas de enrutamiento de red.
tracert: Muestra el camino seguido para llegar a una IP y el tiempo de respuesta de cada nodo.
Varios
at: Permite programar tareas para que nuestro ordenador las ejecute en una fecha o en un momento determinado.
logoff:: Este comando nos permite cerrar una sesión iniciada, ya sea en nuestro ordenador o en otro ordenador remoto.
msg:: Envía un mensaje a unos o varios usuarios determinados mediante su nombre de inicio de sesión o el identificador de su sesión
msiexec:: Permite instalar, desinstalar o reparar un programa instalado mediante un paquete MSI (archivos con extensión .msi).
runas: Permite ejecutar un programa con privilegios de otra cuenta. Útil por ejemplo si estamos como usuario limitado y queremos hacer algo que necesite privilegios de administrador.
shctasks: Permite administrar las tareas programadas.
shutdown: Permite apagar, reiniciar un ordenador o cancelar un apagado. Es especialmente útil si hemos sido infectado con el virus Blaster o una de sus variantes para cancelar la cuenta atrás. Para ello, tan sólo tendremos que utilizar la sintaxis shutdown -a.
Microsoft Management Console (MMC)
Estos comandos nos darán acceso a distintas partes de la Microsoft Management Console, un conjunto de pequeñas aplicaciones que nos permitirán controlar varios apartados de la configuración de nuestro sistema operativo.
Para acceder a estas opciones, no es necesario entrar en la consola del sistema (cmd.exe), sino que basta con introducirlos directamente desde inicio - ejecutar.
ciadv.msc: Permite configurar el servicio de indexado, que acelera las búsquedas en el disco duro.
compmgmt.msc: Da acceso a la Administración de equipos, desde donde podemos configurar nuestro ordenador y acceder a otras partes de la MMC.
devmgmt.msc:: Accede al Administrador de dispositivos.
dfrg.msc: Desfragmentador del disco duro.
diskmgmt.msc: Administrador de discos duros.
fsmgmt.msc: Permite administrar y monitorizar los recursos compartidos.
gpedit.msc: Permite modificar las políticas de grupo.
lusrmgr.msc: Permite ver y modificar los usuarios y grupos locales.
ntmsmgr.msc: Administra y monitoriza los dispositivos de almacenamientos extraíbles.
ntmsoprq.msc: Monitoriza las solicitudes del operador de medios extraíbles.
perfmon.msc: Monitor de rendimiento del sistema.
secpol.msc: Configuración de la política de seguridad local.
services.msc: Administrador de servicios locales.
wmimgmt.msc: Configura y controla el servicio Instrumental de administración (WMI) de Windows.
Como podemos comprobar, muchas de las opciones aquí listadas sólo son accesibles a través de esta consola, por lo que tareas como personalizar nuestro sistema de acuerdo a nuestros gustos, adaptarlo a nuestras necesidades con una mayor precisión o simplemente por conocer cómo funciona nuestro sistema operativo o cómo está configurado podemos realizarlas con ayuda de estos menús ocultos
pchambe2811@gmail.com
Además de las numerosas opciones de configuración que incluye Windows XP en el Panel de Control, existen otras opciones adicionales que sólo son accesibles a través de ciertos comandos.
El sistema operativo Microsoft Windows XP incluye muchas funciones a las que tan sólo podemos acceder a través de la consola de comandos. A menudo estas herramientas nos pueden ayudar a mejorar el rendimiento de nuestro sistema operativo, diagnosticar y corregir problemas o simplemente obtener más información sobre la configuración de nuestro equipo.
Para acceder a la consola de comandos, tan sólo tendremos que ir al menú Inicio, seleccionar la opción ejecutar y escribir cmd.exe ó simplemente cmd. También podremos acceder a este menú mediante la combinación del teclado tecla Windows+R.
Para obtener ayuda adicional sobre un comando, las opciones que incluye y algunos ejemplos de uso, tan sólo tendremos que añadirle la opción /h ó /?.
Archivos y sistemas de ficheros
cacls: Permite modificar los permisos en ficheros y carpetas, permitiendo o prohibiendo a cada usuario leer, escribir o modificar el contenido de dichos archivos o carpetas.
chkdsk: Comprueba el estado de una partición y repara los daños en caso de que encuentre alguno. Si lo ponemos sin ningún parámetro simplemente escaneará la partición, si queremos que además corrija los errores, deberemos añadir la opción /F, es decir, chkdsk /F.
cipher: Permite cifrar archivos, directorios o particiones siempre que se encuentren en el sistema de archivos NTFS.
comp: Compara archivos o carpetas y muestra las diferencias existentes entre ellos.
compact: Permite comprimir archivos o carpetas para ahorrar espacio en el disco duro. Para comprimir los archivos deberemos utilizar el modificador /c y para descomprimirlo en modificador /u. Por ejemplo, para comprimir la carpeta c:\pruebas debemos utilizar el comando compact /c c:\pruebas y para descomprimirla compact /u c:\pruebas.
convert: Convierte particiones FAT ó FAT32 a NTFS. Antes de utilizar este comando es recomendable realizar una copia de seguridad puesto que es posible que durante la conversión se pierdan datos.
defrag: Desfragmenta los archivos de una unidad, similar a la utilidad Defragmentador de discos de Windows pero en modo consola.
diskpart: Permite crear, eliminar y administrar particiones. Este programa en modo consola debemos utilizarlo con cuidado puesto que es fácil que eliminemos sin darnos cuenta todo el contenido del disco duro o de la partición activa.
find y findstr: Estos comandos buscan cadenas de textos en el interior de uno o varios archivos. Sin embargo, el comando findstr ofrece más opciones de búsqueda que el comando find.
iexpress: Este comando lanzará un asistente para crear archivos comprimidos .CAB autodescomprimibles.
openfiles: Muestra a un administrador los archivos abiertos en un sistema a un administrador y permite desconectarlos si se han abierto a través de red.
Configuración del sistema
bootcfg: Permite ver y modificar las entradas del archivo boot.ini. Estas entradas nos permiten seleccionar con que sistema operativo deseamos iniciar el equipo.
control userpasswords2: Permite modificar las claves y los permisos de los diferentes usuarios, así como requerir la pulsación de control+alt+suprimir para poder iniciar sesión, haciendo el inicio de sesión más seguro.
driverquery: Hace un listado de todos los drivers instalados en el sistema y muestra información sobre cada uno de ellos.
dxdiag: Lanza la herramienta de diagnóstico de Direct X, con la cual podremos comprobar la versión Direct X que tenemos instalada y permite comprobar mediante tests que todo lo referente a estos controladores funcione correctamente.
gpresult: Muestra información sobre las políticas de grupo aplicadas a un usuario.
gpupdate: Vuelve a aplicar las políticas de grupo.
msconfig: Desde esta aplicación en modo gráfico podremos seleccionar que programas y servicios se cargan durante el inicio de Windows así como los sistemas operativos que el usuario puede seleccionar para iniciar el ordenador.
pagefileconfig: Permite configurar el archivo de paginación de Windows.
prncnfg: Muestra información sobre las impresoras instaladas
prnjobs: Muestra información sobre los trabajos de impresión en cola.
reg: Permite ver y modificar valores del registro de Windows. Las opciones posibles son:
reg query => realiza una consulta en el registro
reg add => añade una entrada al registro
reg delete => elimina una clave del registro
reg copy => copia una clave del registro a otra parte del registro o a otro equipo
reg save => guarda una parte del registro en un archivo
reg restore => restaura una parte del registro de un archivo
reg load => carga una clave o árbol al registro desde un archivo
reg unload => descarga una clave o árbol del registro
reg compare => compara varios valores del registro
reg export => exporta el registro o parte del registro a un archivo
reg import => importa el registro o parte del registro de un archivo
regedit: Editor del registro en modo gráfico.
sc: Este commando nos permite administrar los servicios, ya sea iniciar uno, detenerlo, mandarle señales, etc.
sfc: Este comando permite buscar archivos del sistema dañados y recuperarlos en caso de que estén defectuosos (es necesario el CD de instalación del sistema operativo para utilizarlo). Para realizar una comprobación inmediata, deberemos ejecutar la orden sfc /scannow.
systeminfo: Muestra información sobre nuestro equipo y nuestro sistema operativo: número de procesadores, tipo de sistema, actualizaciones instaladas, etc.
taskkill: Permite eliminar un proceso conociendo su nombre o el número del proceso (PID).
tasklist: Realiza un listado de todos los procesos que hay. Útil si deseamos eliminar un proceso y no conocemos exactamente su nombre o su PID.
Redes
arp: Muestra y permite modificar las tablas del protocolo ARP, encargado de convertir las direcciones IP de cada ordenador en direcciones MAC (dirección física única de cada tarjeta de red).
ftp: Permite conectarse a otra máquina a través del protocolo FTP para transferir archivos.
getmac: Muestra las direcciones MAC de los adaptadores de red que tengamos instalados en el sistema.
ipconfig: Muestra y permite renovar la configuración de todos los interfaces de red.
nbtstat: Muestra las estadísticas y las conexiones actuales del protocolo NetBIOS sobre TCP/IP, los recursos compartidos y los recursos que son accesibles.
net: Permite administrar usuarios, carpetas compartidas, servicios, etc. Para un listado completo de todas las opciones, escribir net sin ningún argumento. Para obtener ayuda sobre alguna opción en concreto, escribier net help opción.
netsh: Este programa en modo consola permite ver, modificar y diagnosticar la configuración de la red
netstat: Mediante este comando obtendremos un listado de todas las conexiones de red que nuestra máquina ha realizado.
nslookup: Esta aplicación se conecta a nuestros servidores DNS para resolver la IP de cualquier nombre de host. Por ejemplo, si ejecutamos nslookup y escribimos www.hispazone.com, nos responderá con algo como:
Respuesta no autoritativa:
Nombre: www.hispazone.com
Address: 217.76.130.250
Esto quiere decir que la dirección web www.hispazone.com corresponde con la IP 217.76.130.250.
pathping: Muestra la ruta que sigue cada paquete para llegar a una IP determinada, el tiempo de respuesta de cada uno de los nodos por los que pasa y las estadísticas de cada uno de ellos.
ping: Poniendo detrás del comando ping el nombre o la dirección IP de la máquina, por ejemplo ping 192.168.0.1 enviaremos un paquete a la dirección que pongamos para comprobar que está encendida y en red. Además, informa del tiempo que tarda en contestar la máquina destino, lo que nos puede dar una idea de lo congestionada que esté la red.
rasdial: Permite establecer o finalizar una conexión telefónica.
route: Permite ver o modificar las tablas de enrutamiento de red.
tracert: Muestra el camino seguido para llegar a una IP y el tiempo de respuesta de cada nodo.
Varios
at: Permite programar tareas para que nuestro ordenador las ejecute en una fecha o en un momento determinado.
logoff:: Este comando nos permite cerrar una sesión iniciada, ya sea en nuestro ordenador o en otro ordenador remoto.
msg:: Envía un mensaje a unos o varios usuarios determinados mediante su nombre de inicio de sesión o el identificador de su sesión
msiexec:: Permite instalar, desinstalar o reparar un programa instalado mediante un paquete MSI (archivos con extensión .msi).
runas: Permite ejecutar un programa con privilegios de otra cuenta. Útil por ejemplo si estamos como usuario limitado y queremos hacer algo que necesite privilegios de administrador.
shctasks: Permite administrar las tareas programadas.
shutdown: Permite apagar, reiniciar un ordenador o cancelar un apagado. Es especialmente útil si hemos sido infectado con el virus Blaster o una de sus variantes para cancelar la cuenta atrás. Para ello, tan sólo tendremos que utilizar la sintaxis shutdown -a.
Microsoft Management Console (MMC)
Estos comandos nos darán acceso a distintas partes de la Microsoft Management Console, un conjunto de pequeñas aplicaciones que nos permitirán controlar varios apartados de la configuración de nuestro sistema operativo.
Para acceder a estas opciones, no es necesario entrar en la consola del sistema (cmd.exe), sino que basta con introducirlos directamente desde inicio - ejecutar.
ciadv.msc: Permite configurar el servicio de indexado, que acelera las búsquedas en el disco duro.
compmgmt.msc: Da acceso a la Administración de equipos, desde donde podemos configurar nuestro ordenador y acceder a otras partes de la MMC.
devmgmt.msc:: Accede al Administrador de dispositivos.
dfrg.msc: Desfragmentador del disco duro.
diskmgmt.msc: Administrador de discos duros.
fsmgmt.msc: Permite administrar y monitorizar los recursos compartidos.
gpedit.msc: Permite modificar las políticas de grupo.
lusrmgr.msc: Permite ver y modificar los usuarios y grupos locales.
ntmsmgr.msc: Administra y monitoriza los dispositivos de almacenamientos extraíbles.
ntmsoprq.msc: Monitoriza las solicitudes del operador de medios extraíbles.
perfmon.msc: Monitor de rendimiento del sistema.
secpol.msc: Configuración de la política de seguridad local.
services.msc: Administrador de servicios locales.
wmimgmt.msc: Configura y controla el servicio Instrumental de administración (WMI) de Windows.
Como podemos comprobar, muchas de las opciones aquí listadas sólo son accesibles a través de esta consola, por lo que tareas como personalizar nuestro sistema de acuerdo a nuestros gustos, adaptarlo a nuestras necesidades con una mayor precisión o simplemente por conocer cómo funciona nuestro sistema operativo o cómo está configurado podemos realizarlas con ayuda de estos menús ocultos
pchambe2811@gmail.com
COMANDOS ATTRIB,MD,CD,RD,EXIT,DEL,ERASE

C:\Documents and Settings\Makina06>help md
Crea un directorio.
MKDIR [unidad:]ruta
MD [unidad:]ruta
Si las extensiones de comandos están habilitadas, MKDIR cambia así:
MKDIR crea cualquier directorio intermedio de la ruta de acceso siempre
que sea necesario. Por ejemplo, si \a no existe:
mkdir \a\b\c\d
es lo mismo que:
mkdir \a
chdir \a
mkdir b
chdir b
mkdir c
chdir c
mkdir d
que es lo que hubiese tenido que escribir si no se hubiese habilitado las
Presione una tecla para continuar . . .
C:\Documents and Settings\Makina06>help cd
Muestra el nombre del directorio actual o cambia de directorio.
CHDIR [/D] [unidad:][ruta]
CHDIR [..]
CD [/D] [unidad:][ruta]
CD [..]
.. Especifica que desea cambiar al directorio superior.
Escriba CD unidad: para ver el directorio actual de la unidad especificada.
Escriba CD sin parámetros para ver la unidad y el directorio actual.
Use el modificador /D para cambiar la unidad actual además del directorio
actual para una unidad de disco.
Si las extensiones de comando están habilitadas, CHDIR cambia así:
El uso de mayúsculas y minúsculas de la cadena del directorio actual se
convierte al mismo uso que se tiene en los nombres de unidades. Así, CD
C:\TEMP establecerá C:\Temp como el directorio actual si éste es el uso
de mayúsculas y minúsculas en la unidad.
El comando CHDIR no trata los espacios como separadores, así que es posible
C:\Documents and Settings\Makina06>help rd
Quita un directorio.
RMDIR [/S] [/Q] [unidad:]ruta
RD [/S] [/Q] [unidad:]ruta
/S Quita todos los directorios y archivos del directorio además
del mismo directorio. Se utiliza principalmente cuando se
desea quitar un árbol.
/Q Modo silencioso, no pide confirmación para quitar un árbol
de directorio con /S
C:\Documents and Settings\Makina06>HELP DEL
Elimina uno o más archivos.
DEL [/P] [/F] [/S] [/Q] [/A[[:]atributos]] nombres
ERASE [/P] [/F] [/S] [/Q] [/A[[:]atributos]] nombres
nombres Especifica una lista de uno o más archivos o directorios.
Se puede utilizar comodines para eliminar varios archivos.
Si se especifica un directorio todos sus archivos se eliminarán.
/P Pide confirmación antes de eliminar cada archivo.
/F Fuerza la eliminación de archivos de sólo lectura.
/S Elimina archivos especificados en todos los subdirectorios.
/Q Modo silencioso. No pide confirmación con comodín global
/A Selecciona los archivos que se van a eliminar basándose en los
atributos
atributos R Archivos de sólo lectura S Archivos de sistema
H Archivos ocultos A Archivos preparados para
almacenamiento
- Prefijo de exclusión
Si las extensiones de comando están activadas DEL y ERASE cambian de la siguient
e manera:
C:\Documents and Settings\Makina06>HELP ERASE
Elimina uno o más archivos.
DEL [/P] [/F] [/S] [/Q] [/A[[:]atributos]] nombres
ERASE [/P] [/F] [/S] [/Q] [/A[[:]atributos]] nombres
nombres Especifica una lista de uno o más archivos o directorios.
Se puede utilizar comodines para eliminar varios archivos.
Si se especifica un directorio todos sus archivos se eliminarán.
/P Pide confirmación antes de eliminar cada archivo.
/F Fuerza la eliminación de archivos de sólo lectura.
/S Elimina archivos especificados en todos los subdirectorios.
/Q Modo silencioso. No pide confirmación con comodín global
/A Selecciona los archivos que se van a eliminar basándose en los
atributos
atributos R Archivos de sólo lectura S Archivos de sistema
H Archivos ocultos A Archivos preparados para
almacenamiento
- Prefijo de exclusión
Si las extensiones de comando están activadas DEL y ERASE cambian de la siguient
e manera:
C:\Documents and Settings\Makina06>HELP EXIT
Abandona el programa CMD.EXE (intérprete de comandos) o el archivo de
comandos por lotes actual.
EXIT [/B] [código]
/B especifica que se debe abandonar el archivo de procesos por
lotes actual y no CMD.EXE. Si se ejecuta desde fuera de un
archivo de procesos por lotes, abandonará CMD.EXE
código especifica un número. Si se ha especificado /B, establece
ERRORLEVEL con este número. Si abandona CMD.EXE, establece
el código de salida del proceso con este número.
C:\Documents and Settings\Makina06>HELP ATTRIB
Muestra o cambia los atributos de un archivo.
ATTRIB [+R | -R] [+A | -A ] [+S | -S] [+H | -H] [unidad:][ruta]
[nombre-archivo] [/S [/D]]
+ Establece un atributo.
- Borra un atributo.
R Atributo de sólo lectura del archivo.
A Atributo de archivo de almacenamiento.
S Atributo de archivos del sistema.
H Atributo de archivo oculto.
[unidad:][ruta][nombre-archivo]
Especifica el archivo o archivos que serán afectados por ATTRIB
/S Procesa archivos que coinciden en la carpeta actual
y todas las carpetas.
/D Procesa carpetas.
viernes, 27 de noviembre de 2009
SISTAMA BINARIO,DECIMAL,HEXADECIMAL Y OCTAL

Sistema decimal
El sistema decimal es un sistema de numeración en el que las cantidades se representan utilizando como base el número diez, por lo que se compone de diez cifras diferentes: cero (0); uno (1); dos (2); tres (3); cuatro (4); cinco (5); seis (6); siete (7); ocho (8) y nueve (9). Este conjunto de símbolos se denomina números árabes, y es de origen indio.
Es el sistema de numeración usado habitualmente en todo el mundo (excepto ciertas culturas) y en todas las áreas que requieren de un sistema de numeración. Sin embargo hay ciertas técnicas, como por ejemplo en la informática, donde se utilizan sistemas de numeración adaptados al método de trabajo como el binario o el hexadecimal. También pueden existir en algunos idiomas vestigios del uso de otros sistemas de numeración, como el quinario, el duodecimal y el vigesimal. Por ejemplo, cuando se cuentan artículos por docenas, o cuando se emplean palabras especiales para designar ciertos números (en francés, por ejemplo, el número 80 se expresa como "cuatro veintenas").
Según los antropólogos, el origen del sistema decimal está en los diez dedos que tenemos los humanos en las manos, los cuales siempre nos han servido de base para contar.
El sistema decimal es un sistema de numeración posicional, por lo que el valor del dígito depende de su posición dentro del número. Así:
Los números decimales se pueden representar en rectas numéricas.
Sistema binario
El sistema binario, en matemáticas e informática, es un sistema de numeración en el que los números se representan utilizando solamente las cifras cero y uno (0 y 1). Es el que se utiliza en los ordenadores, pues trabajan internamente con dos niveles de voltaje, por lo que su sistema de numeración natural es el sistema binario (encendido 1, apagado 0).
Representación
Un número binario puede ser representado por cualquier secuencia de bits (dígitos binarios), que a su vez pueden ser representados por cualquier mecanismo capaz de estar en dos estados mutuamente exclusivos. Las secuencias siguientes de símbolos podrían ser interpretadas todas como el mismo valor binario numérico:
1 0 1 0 0 1 1 0 1 0
| - | - - | | - | -
x o x o o x x o x o
y n y n n y y n y n
El valor numérico representado en cada caso depende del valor asignado a cada símbolo. En un ordenador, los valores numéricos pueden ser representados por dos voltajes diferentes y también se pueden usar polaridades magnéticas sobre un disco magnético. Un "positivo", "sí", o "sobre el estado" no es necesariamente el equivalente al valor numérico de uno; esto depende de la arquitectura usada.
De acuerdo con la representación acostumbrada de cifras que usan números árabes, los números binarios comúnmente son escritos usando los símbolos 0 y 1. Cuando son escritos, los números binarios son a menudo subindicados, prefijados o sufijados para indicar su base, o la raíz. Las notaciones siguientes son equivalentes:
• 100101 binario (declaración explícita de formato)
• 100101b (un sufijo que indica formato binario)
• 100101B (un sufijo que indica formato binario)
• bin 100101 (un prefijo que indica formato binario)
• 1001012 (un subíndice que indica base 2 (binaria) notación)
• %100101 (un prefijo que indica formato binario)
• 0b100101 (un prefijo que indica formato binario, común en lenguajes de programación)
Sistema octal
El sistema numérico en base 8 se llama octal y utiliza los dígitos 0 a 7.
Por ejemplo, el número binário para 74 (en decimal) es 1001010 (en binario), lo agruparíamos como 1 / 001 / 010, de tal forma que obtengamos una serie de números en binário de 3 dígitos cada uno (para fragmentar el número se comienza desde el primero por la derecha y se parte de 3 en 3), despues obtenemos el número en decimal de cada uno de los números en binario obtenidos: 1=1, 001=1 y 010=2. De modo que el número decimal 74 en octal es 112.
Hay que hacer notar que antes de poder pasar un número a octal es necesario pasar por el binario. Para llegar al resultado de 74 en octal se sigue esta serie: Decimal -> Binario -> Octal.
En informática, a veces se utiliza la numeración octal en vez de la hexadecimal. Tiene la ventaja de que no requiere utilizar otros símbolos diferentes de los dígitos. Sin embargo, para trabajar con bytes o conjuntos de ellos, asumiendo que un byte es una palabra de 8 bits, suele ser más cómodo el sistema hexadecimal, por cuanto todo byte así definido es completamente representable por dos dígitos hexadecimales.
Es posible que la numeración octal se usara en el pasado en lugar del decimal, por ejemplo, para contar los espacios interdigitales o los dedos distintos de los pulgares.
Sistema hexadecimal
Tabla de multiplicar hexadecimal.
El sistema hexadecimal, a veces abreviado como hex, es el sistema de numeración posicional de base 16 —empleando por tanto 16 símbolos—. Su uso actual está muy vinculado a la informática y ciencias de la computación, pues los computadores suelen utilizar el byte u octeto como unidad básica de memoria; y, debido a que un byte representa 28 valores posibles, y esto puede representarse como , que, según el teorema general de la numeración posicional, equivale al número en base 16 10016, dos dígitos hexadecimales corresponden exactamente —permiten representar la misma línea de enteros— a un byte.
En principio dado que el sistema usual de numeración es de base decimal y, por ello, sólo se dispone de diez dígitos, se adoptó la convención de usar las seis primeras letras del alfabeto latino para suplir los dígitos que nos faltan. El conjunto de símbolos sería, por tanto, el siguiente:
Se debe notar que A = 10, B = 11, C = 12, D = 13, E = 14 y F = 15. En ocasiones se emplean letras minúsculas en lugar de mayúsculas. Como en cualquier sistema de numeración posicional, el valor numérico de cada dígito es alterado dependiendo de su posición en la cadena de dígitos, quedando multiplicado por una cierta potencia de la base del sistema, que en este caso es 16. Por ejemplo: 3E0A16 = 3×162 + E×161 + 0×160 + A×16-1 = 3×256 + 14×16 + 0×1 + 10×0,0625 = 992,625.
El sistema hexadecimal actual fue introducido en el ámbito de la computación por primera vez por IBM en 1963. Una representación anterior, con 0–9 y u–z, fue usada en 1956 por la computadora Bendix G-15.
UBUNTU Y COMANDOS
UBUNTU
Escritorio de Ubuntu 9.10 "Karmic Koala"
Ubuntu (AFI: /uˈbuntu/), o Ubuntu Linux, es una distribución Linux basada en Debian GNU/Linux, cuyo nombre proviene de la ideología sudafricana Ubuntu ("humanidad hacia otros").6
Proporciona un sistema operativo actualizado y estable para el usuario promedio, con un fuerte enfoque en la facilidad de uso y de instalación del sistema. Al igual que otras distribuciones se compone de múltiples paquetes de software normalmente distribuidos bajo una licencia libre o de código abierto.
Ubuntu está patrocinando por Canonical Ltd., una compañía británica propiedad del empresario sudafricano Mark Shuttleworth que en vez de vender la distribución con fines lucrativos, se financia por medio de servicios vinculados al sistema operativo7 8 y vendiendo soporte técnico.9 Además, al mantenerlo libre y gratuito, la empresa es capaz de aprovechar el talento de los desarrolladores de la comunidad en mejorar los componentes de su sistema operativo. Canonical también apoya y proporciona soporte para tres derivaciones de Ubuntu: Kubuntu, Edubuntu y la versión de Ubuntu orientada a servidores ("Ubuntu Server Edition").10
Cada seis meses se libera una nueva versión de Ubuntu la cual recibe soporte por parte de Canonical, durante dieciocho meses, por medio de actualizaciones de seguridad, parches para bugs críticos y actualizaciones menores de programas. Las versiones LTS (Long Term Support), que se liberan cada dos años,11 reciben soporte durante tres años en los sistemas de escritorio y cinco para la edición orientada a servidores.12
Ubuntu fue seleccionado por los lectores de desktoplinux.com como una de las distribuciones más populares, llegando a alcanzar aproximadamente el 30% de las instalaciones de Linux en computadoras de escritorio tanto en 200613 como en 2007.14
La versión actual de Ubuntu, 9.10 ("Karmic Koala"), se liberó el 29 de octubre de 200915 y la próxima versión, 10.04 (nombre en código: Lucid Lynx), se espera que vea la luz en abril de 2010.
Los Comandos
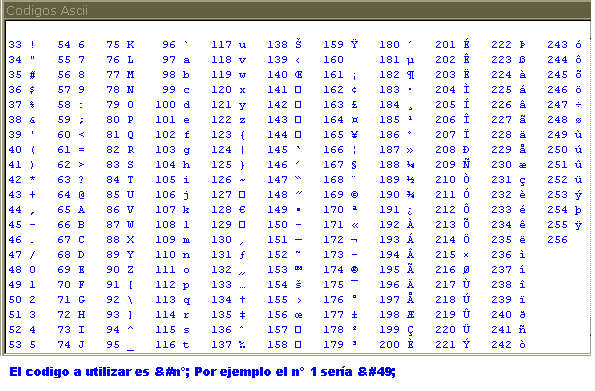
1~MSD
Acrónimo de Microsoft Diagnostics (diagnósticos de Microsoft) Nombre que recibe la aplicación entregada en las últimas versiones del sistema operativo MS-DOS, que posibilita al usuario la obtención de informaciónsobre la configuración de su equipo.
MS-DOS(Microsoft-disk operating system)
Sistema operativoen disco de Microsoft sistemaoperativo de un solo usuario para PC de Microsoft, es casi la versión idéntica de IBM, que se llama *Dos* genéricamente.
2~FORMAT(comando externo)
Sistema operativo de Microsoft por encargo de IBM, para equipar a los ordenadores PC que había desarrollado.
Format: comando del sistema operativo MS-DOS cuya misión es formatear las unidades de almacenamiento (discos duros y disquetes).
Formatear es preparar un disco o disquete para trabajar o almacenar datos.
Este tiene como objetivo dar formato al disco del driver. Este crea un nuevo directorio raíz y tabla de asignación de archivos para el disco. También puede verificar si hay factores defectuosos en el disco y podrá borrar toda la información que este contenga.
3~CLS(comando interno)
Comando del sistema operativo MS-DOS cuya misión es limpiar la pantalla. Una vez limpia la pantalla coloca el cursor en la parte superior izquierda de la misma.
4~CD (comando externo)
Comando de los sistemas operativos DOS y UNIX que nos sirve para cambiar de escritorio.
5~MD
Crea un directorio
6~ROOT
Es un sistema operativo jerárquico de archivos refiérese al primer escritorio respecto al cual todos los demás son subdirectorios.
7~ DISKCOPY(comando externo)
Nos permite hacer una copia idéntica de un disquete a otro, pertenece al grupo de los comandos externos.
8~Comandos Internos
Son aquellos comandos cuyas instrucciones son cargadas a la memoria RAM. Estos comandos no necesitan la presencia del disco de sistema operativo. Entre ellos encontramos:
COPY CLS
DEL O ERASE DIR
TYPE DATE
RENAME MD
TIME VER
9. Comandos Externos
Estos comandos necesitan mucha capacidad de memoria para mantenerse dentro de ella al mismo tiempo, por lo tanto son grabados en el disco, y podemos ascesarlos cuando sea necesario. Son llamados externos porque estos están grabados fuera de la memoria RAM. Entre estos están:
CLRDSK DISP COMP
DELTREE TREE
DOSKEY RESTORE
FORMAT DISK COPY
ATTRIB LAVEL
10~ FAT (file allocation table) (comando interno)
Tabla de asignación de archivos. Es la parte del sistema de archivo DOS y OS/2 que lleva la cuenta de donde están almacenados los datos en el disco.
11~PROMPT(símbolo del sistema) (comando interno).
Este cambia la línea de comando, o sea, se emplea para cambiar la visualización de la línea de comando.
12~PATH(comando interno)
Especifica el directorio cuya estructura del directorio desee preguntar.
13-14~Erase O Delete(comandos internos)
Este comando se utiliza para suprimir, borrar o eliminar uno mas archivos de un disquete o disco duro. Otro comando que tiene la misma función es el comando interno ERASE.
15~COPY(comando interno)
Copia uno o más archivos de un disquete a otro. Este comando también puede emplearse como un editor de texto.
16~ATTRIB(comando interno)
Brinda atributos a los archivos. Despliega o cambia los atributos de los archivos.
Ej.
TH- atributo de invisibilidad
R-atributo de solo lectura
T-activa un atributo
M-desactiva un atributo
17~XCOPY
Comando que permite hacer copias del disco duro o entre disquetes distintos formato. XCOPY lee todos los ficheros que una memoria RAM y a continuación lo escribe en un disquete.
18~VER (comando interno)
Su objetivo es visualizar la versión del sistema operativo en el disco. Despliega información de la versión del DOS que esta operando la computadora.
19~VOL(comando interno)
Tiene como objetivo mostrar el volumen del disco y su numero de serie si existen.
20~DOS KEY(comando externo)
Nos permite mantener residente en memoria RAM las ordenes que han sido ejecutadas en el punto indicativo.
21~PRINT
Comando que nos permite imprimir varios ficheros de textos sucesivamente.
22~MIRROR
Al grabar cualquier archivo en Array de unidades en espejo el controlador envía simultáneamente copias idénticas del archivo a
cada unidad del array el cual puede constar únicamente de dos unidades.
23~BACK UP(comando externo)
Ejecuta una copia de seguridadde uno o más archivos de un disco duro a un disquete.
24~RESTORE
Este comando restaura los archivos que se hagan hecho copia de seguridad
25~BUFFERS
Son unidades de memoria reservadas para conservar informaciones intercambiadas con las computadoras.
26~SCANDISK
Sirve para comprobar si hay errores físicos y lógicos en el computador.
27~SLASH
Comando que cierra el directorio hacia la raíz.
28~BACK SLASH
Comando que pasa de un directorio a otro principal.
29~CONFIG. SYS
Copia los archivos del sistema y el interpretador de comandos al disco que especifique.
30~AUTO EXE BAT
Es el primer fichero que el MS-DOS ejecuta.
31~UNDELETE
Proporciona una proporción de distintos niveles para ficheros borrados.
32~`UNFORMAT
Comando que permite reconstruir un disco recuperando así toda la información que contenga.
33~DIR
Sirve para ver los archivos, directorios y subdirectorios que se encuentran en el disco duro o en un disquete.
34~COMADINES
Son caracteres que facilitan el manejo de los comandos Ej.
?- un carácter
*- un grupo de caracteres
35~F DISK
Permite crear varias peticiones en un disco duro y seleccionar, cual de ellas será la partición, es simplemente una división del disco duro que el MS-DOS trata como un área individual de acceso.
36~LABEL(comando externo)
Etiqueta el disco. Una etiqueta es el nombre de un dato, archivo o programa.
37~SYS(comando externo)
Transfiere los archivos de sistema de dos ocultos para hacer un disquete que tenia para inicial.
38~TIME(comando interno)
Tiene como objetivo visualizar la hora del sistema o ejecutar el reloj interno de la PC.
39~DATE(comando interno)
Permite modificar y visualizar la fecha del sistema.
40~DELTREE(comando externo)
Usado para borrar un directorio raíz no importa que contenga subdirectorios con todos sus contenidos.
41~TREE(comando externo)
Su función es presentar en forma gráfica la estructura de un directorio raíz.
42~TYPE(comando interno)
Visualiza el contenido de un archivo Desde la línea de comando. O sea las informaciones que posee un archivo en su interior.
43~EDIT
Inicia el editor del DOS, para trabajar con archivos ASCII.
44~REN(rename)
Renombra uno o más archivos, no se puede especificar otro disco o ruta para el o los archivos.
45~RD(rmdir)
Remueve o borra directorios, para borrar el directorio debe estar en blanco.
SISTEMA OPERATIVO

Sistema operativo
Intereaccion entre el SO con el resto de las partes.
Un sistema operativo es un software de sistema, es decir, un conjunto de programas de computación destinados a realizar muchas tareas entre las que destaca la administración de los dispositivos periféricos.
Cuando se aplica voltaje al procesador de un dispositivo electrónico, éste ejecuta un reducido código en lenguaje ensamblador localizado en una dirección concreta en la ROM (dirección de reset) y conocido como reset code, que a su vez ejecuta una rutina con la que se inicializa el hardware que acompaña al procesador. También en esta fase suele inicializarse el controlador de las interrupciones. Finalizada esta fase se ejecuta el código de arranque (startup code), también código en lenguaje ensamblador, cuya tarea más importante es ejecutar el programa principal (main()) del software de la aplicación.1
Un sistema operativo se puede encontrar en la mayoría de los aparatos electrónicos que utilicen microprocesadores para funcionar, ya que gracias a éstos podemos entender la máquina y que ésta cumpla con sus funciones (teléfonos móviles, reproductores de DVD, autoradios, computadoras, radios, etc).
Funciones básicas
Los sistemas operativos, en su condición de capa software que posibilitan y simplifica el manejo de la computadora, desempeñan una serie de funciones básicas esenciales para la gestión del equipo. Entre las más destacables, cada una ejercida por un componente interno (módulo en núcleos monolíticos y servidor en micronúcleos), podemos reseñar las siguientes:
• Proporcionar más comodidad en el uso de un computador.
• Gestionar de manera eficiente los recursos del equipo, ejecutando servicios para los procesos (programas)
• Brindar una interfaz al usuario, ejecutando instrucciones (comandos).
• Permitir que los cambios debidos al desarrollo del propio SO se puedan realizar sin interferir con los servicios que ya se prestaban (evolutividad).
Un sistema operativo desempeña 5 funciones básicas en la operación de un sistema informático: suministro de interfaz al usuario, administración de recursos, administración de archivos, administración de tareas y servicio de soporte y utilidades.
Interfaces del usuario
Es la parte del sistema operativo que permite comunicarse con él, de tal manera que se puedan cargar programas, acceder archivos y realizar otras tareas. Existen tres tipos básicos de interfaces: las que se basan en comandos, las que utilizan menús y las interfaces gráficas de usuario.
Administración de recursos
Sirven para administrar los recursos de hardware y de redes de un sistema informático, como la CPU, memoria, dispositivos de almacenamiento secundario y periféricos de entrada y de salida.
Administración de archivos
Un sistema de información contiene programas de administración de archivos que controlan la creación, borrado y acceso de archivos de datos y de programas. También implica mantener el registro de la ubicación física de los archivos en los discos magnéticos y en otros dispositivos de almacenamiento secundarios.
Administración de tareas
Los programas de administración de tareas de un sistema operativo administran la realización de las tareas informáticas de los usuarios finales. Los programas controlan qué áreas tienen acceso al CPU y por cuánto tiempo. Las funciones de administración de tareas pueden distribuir una parte específica del tiempo del CPU para una tarea en particular, e interrumpir al CPU en cualquier momento para sustituirla con una tarea de mayor prioridad.
Servicio de soporte
Los servicios de soporte de cada sistema operativo dependerán de la implementación particular de éste con la que estemos trabajando. Entre las más conocidas se pueden destacar las implementaciones de Unix, desarrolladas por diferentes empresas de software, los sistemas operativos de Apple Inc., como Mac OS X para las computadoras de Apple Inc., los sistemas operativos de Microsoft, y las implementaciones de software libre, como GNU/Linux o BSD producidas por empresas, universidades, administraciones públicas, organizaciones sin fines de lucro y/o comunidades de desarrollo.
Estos servicios de soporte suelen consistir en:
• Actualización de versiones.
• Mejoras de seguridad.
• Inclusión de alguna nueva utilidad (un nuevo entorno gráfico, un asistente para administrar alguna determinada función, ...).
• Controladores para manejar nuevos periféricos (este servicio debe coordinarse a veces con el fabricante del hardware).
• Corrección de errores de software.
• Otros.
No todas las utilidades de administración o servicios forman parte del sistema operativo, además de éste, hay otros tipos importantes de software de administración de sistemas, como los sistemas de administración de base de datos o los programas de administración de redes. El soporte de estos productos deberá proporcionarlo el fabricante correspondiente (que no tiene porque ser el mismo que el del sistema operativo).
Perspectiva histórica
Estimación del uso actual de sistemas operativos según una muestra de computadoras con acceso a Internet (Fuente: W3counter).
Los primeros sistemas (1945 - 1950) eran grandes máquinas operadas desde la consola maestra por los programadores. Durante la década siguiente (1950 - 1960) se llevaron a cabo avances en el hardware: lectoras de tarjetas, impresoras, cintas magnéticas, etc. Esto a su vez provocó un avance en el software: compiladores, ensambladores, cargadores, manejadores de dispositivos, etc.
[editar] Problemas de explotación y soluciones iniciales
El problema principal de los primeros sistemas era la baja utilización de los mismos, la primera solución fue poner un operador profesional que manejaba el sistema, con lo que se eliminaron las hojas de reserva, se ahorró tiempo y se aumentó la velocidad.
Para ello, los trabajos se agrupaban de forma manual en lotes mediante lo que se conoce como procesamiento por lotes (batch) sin automatizar.
Monitores residentes
Fichas en lenguaje de procesamiento por lotes, con programa y datos, para ejecución secuencial
Según fue avanzando la complejidad de los programas, fue necesario implementar soluciones que automatizaran la organización de tareas sin necesidad de un operador. Debido a ello se crearon los monitores residentes: programas que residían en memoria y que gestionaban la ejecución de una cola de trabajos.
Un monitor residente estaba compuesto por un cargador, un Intérprete de comandos y un Controlador (drivers) para el manejo de entrada/salida.
Sistemas con almacenamiento temporal de E/S
Se avanza en el hardware, creando el soporte de interrupciones. Luego se lleva a cabo un intento de solución más avanzado: solapar la E/S de un trabajo con sus propios cálculos. Por ello se crea el sistema de buffers con el siguiente funcionamiento:
• Un programa escribe su salida en un área de memoria (buffer 1).
• El monitor residente inicia la salida desde el buffer y el programa de aplicación calcula depositando la salida en el buffer 2.
• La salida desde el buffer 1 termina y el nuevo cálculo también.
• Se inicia la salida desde el buffer 2 y otro nuevo cálculo dirige su salida al buffer 1.
• El proceso se puede repetir de nuevo.
Los problemas surgen si hay muchas más operaciones de cálculo que de E/S (limitado por la CPU) o si por el contrario hay muchas más operaciones de E/S que cálculo (limitado por la E/S).
Spoolers
Hace aparición el disco magnético con lo que surgen nuevas soluciones a los problemas de rendimiento. Se eliminan las cintas magnéticas para el volcado previo de los datos de dispositivos lentos y se sustituyen por discos (un disco puede simular varias cintas). Debido al solapamiento del cálculo de un trabajo con la E/S de otro trabajo se crean tablas en el disco para diferentes tareas, lo que se conoce como Spool (Simultaneous Peripherial Operation On-Line).
Sistemas Operativos Multiprogramados
Surge un nuevo avance en el hardware: el hardware con protección de memoria. Lo que ofrece nuevas soluciones a los problemas de rendimiento:
• Se solapa el cálculo de unos trabajos con la entrada/salida de otros trabajos.
• Se pueden mantener en memoria varios programas.
• Se asigna el uso de la CPU a los diferentes programas en memoria.
Debido a los cambios anteriores, se producen cambios en el monitor residente, con lo que éste debe abordar nuevas tareas, naciendo lo que se denomina como Sistemas Operativos multiprogramados, los cuales cumplen con las siguientes funciones:
• Administrar la memoria.
• Gestionar el uso de la CPU (planificación).
• Administrar el uso de los dispositivos de E/S.
Cuando desempeña esas tareas, el monitor residente se transforma en un sistema operativo multiprogramado.
Llamadas al Sistema Operativo
Definición breve: llamadas que ejecutan los programas de aplicación para pedir algún servicio al SO.
Cada SO implementa un conjunto propio de llamadas al sistema. Ese conjunto de llamadas es el interfaz del SO frente a las aplicaciones. Constituyen el lenguaje que deben usar las aplicaciones para comunicarse con el SO. Por ello si cambiamos de SO, y abrimos un programa diseñado para trabajar sobre el anterior, en general el programa no funcionará, a no ser que el nuevo SO tenga la misma interfaz. Para ello:
• Las llamadas correspondientes deben tener el mismo formato.
• Cada llamada al nuevo SO tiene que dar los mismos resultados que la correspondiente del anterior.
Modos de ejecución en un CPU
Las aplicaciones no deben poder usar todas las instrucciones de la CPU. No obstante el SO, tiene que poder utilizar todo el juego de instrucciones del CPU. Por ello, una CPU debe tener (al menos) dos modos de operación diferentes:
• Modo usuario: el CPU podrá ejecutar sólo las instrucciones del juego restringido de las aplicaciones.
• Modo supervisor: la CPU debe poder ejecutar el juego completo de instrucciones.
Llamadas al Sistema
Una aplicación, normalmente no sabe dónde está situada la rutina de servicio de la llamada. Por lo que si ésta se codifica como una llamada de función, cualquier cambio en el SO haría que hubiera que reconstruir la aplicación.
Pero lo más importante es que una llamada de función no cambia el modo de ejecución de la CPU. Con lo que hay que conseguir llamar a la rutina de servicio, sin tener que conocer su ubicación, y hacer que se fuerce un cambio de modo de operación de la CPU en la llamada (y la recuperación del modo anterior en el retorno).
Esto se hace utilizando instrucciones máquina diseñadas específicamente para este cometido, distintas de las que se usan para las llamadas de función.
Bibliotecas de interfaz de llamadas al sistema
Las llamadas al sistema no siempre tienen una expresión sencilla en los lenguajes de alto nivel, por ello se crean las bibliotecas de interfaz, que son bibliotecas de funciones que pueden usarse para efectuar llamadas al sistema. Las hay para distintos lenguajes de programación.
La aplicación llama a una función de la biblioteca de interfaz (mediante una llamada normal) y esa función es la que realmente hace la llamada al sistema.
MICROPROCESADOR,BUSES Y TIPOS DE MEMORIAS

Microprocesador
Uno de los actuales microprocesadores de 64 bits y doble núcleo, un AMD Athlon 64 X2 3600.El microprocesador es un circuito integrado que contiene algunos o todos los elementos hardware, y el de CPU, que es un concepto lógico. Una CPU puede estar soportada por uno o varios microprocesadores, y un microprocesador puede soportar una o varias CPU. Un núcleo suele referirse a una porción del procesador que realiza todas las actividades de una CPU real.
La tendencia de los últimos años ha sido la de integrar más núcleos dentro de un mismo empaque, además de componentes como memorias Cache y controladores de memoria, elementos que antes estaban montados sobre la placa base como dispositivos individuales.
Bus (informática)
Buses de comunicación en un circuito impreso
En arquitectura de computadores, el bus es un sistema digital que transfiere datos entre los componentes de un ordenador o entre ordenadores. Está formado por cables o pistas en un circuito impreso, dispositivos como resistencias y condensadores además de circuitos integrados. En los primeros computadores electrónicos, todos los buses eran de tipo paralelo, de manera que la comunicación entre las partes de computador se hacía por medio de cintas o muchas pistas en el circuito impreso, en los cuales cada conductor tiene una función fija y la conexión es sencilla requiriendo únicamente puertos de entrada y de salida para cada dispositivo.
La tendencia en los últimos años es el uso de buses seriales como el USB, Custom Firewire para comunicaciones con periféricos y el reemplazo de buses paralelos para conectar toda clase de dispositivos, incluyendo el microprocesador con el chipset en la propia placa base. Son conexiones con lógica compleja que requieren en algunos casos gran poder de computo en los propios dispositivos, pero que poseen grandes ventajas frente al bus paralelo que es menos inteligente.
Existen diversas especificaciones de bus que definen un conjunto de características mecánicas como conectores, cables y tarjetas, además de protocolos eléctricos y de señales.
Tipos de memorias
DRAM: acrónimo de "Dynamic Random Access Memory", o simplemente RAM ya que es la original, y por tanto la más lenta.
Usada hasta la época del 386, su velocidad de refresco típica es de 80 ó 70 nanosegundos (ns), tiempo éste que tarda en vaciarse para poder dar entrada a la siguiente serie de datos. Por ello, la más rápida es la de 70 ns. Físicamente, aparece en forma de DIMMs o de SIMMs, siendo estos últimos de 30 contactos.
FPM (Fast Page Mode): a veces llamada DRAM, puesto que evoluciona directamente de ella, y se usa desde hace tanto que pocas veces se las diferencia. Algo más rápida, tanto por su estructura (el modo de Página Rápida) como por ser de 70 ó 60 ns. Es lo que se da en llamar la RAM normal o estándar. Usada hasta con los primeros Pentium, físicamente aparece como SIMMs de 30 ó 72 contactos (los de 72 en los Pentium y algunos 486).
Para acceder a este tipo de memoria se debe especificar la fila (página) y seguidamente la columna. Para los sucesivos accesos de la misma fila sólo es necesario especificar la columna, quedando la columna seleccionada desde el primer acceso. Esto hace que el tiempo de acceso en la misma fila (página) sea mucho más rápido. Era el tipo de memoria normal en los ordenadores 386, 486 y los primeros Pentium y llegó a alcanzar velocidades de hasta 60 ns. Se presentaba en módulos SIMM de 30 contactos (16 bits) para los 386 y 486 y en módulos de 72 contactos (32 bits) para las últimas placas 486 y las placas para Pentium.
EDO o EDO-RAM: Extended Data Output-RAM. Evoluciona de la FPM. Permite empezar a introducir nuevos datos mientras los anteriores están saliendo (haciendo su Output), lo que la hace algo más rápida (un 5%, más o menos). Mientras que la memoria tipo FPM sólo podía acceder a un solo byte (una instrucción o valor) de información de cada vez, la memoria EDO permite mover un bloque completo de memoria a la caché interna del procesador para un acceso más rápido por parte de éste. La estándar se encontraba con refrescos de 70, 60 ó 50 ns. Se instala sobre todo en SIMMs de 72 contactos, aunque existe en forma de DIMMs de 168.
La ventaja de la memoria EDO es que mantiene los datos en la salida hasta el siguiente acceso a memoria. Esto permite al procesador ocuparse de otras tareas sin tener que atender a la lenta memoria. Esto es, el procesador selecciona la posición de memoria, realiza otras tareas y cuando vuelva a consultar la DRAM los datos en la salida seguirán siendo válidos. Se presenta en módulos SIMM de 72 contactos (32 bits) y módulos DIMM de 168 contactos (64 bits).
SDRAM: Sincronic-RAM. Es un tipo síncrono de memoria, que, lógicamente, se sincroniza con el procesador, es decir, el procesador puede obtener información en cada ciclo de reloj, sin estados de espera, como en el caso de los tipos anteriores. Sólo se presenta en forma de DIMMs de 168 contactos; es la opción para ordenadores nuevos.
SDRAM funciona de manera totalmente diferente a FPM o EDO. DRAM, FPM y EDO transmiten los datos mediante señales de control, en la memoria SDRAM el acceso a los datos esta sincronizado con una señal de reloj externa.
La memoria EDO está pensada para funcionar a una velocidad máxima de BUS de 66 Mhz, llegando a alcanzar 75MHz y 83 MHz. Sin embargo, la memoria SDRAM puede aceptar velocidades de BUS de hasta 100 MHz, lo que dice mucho a favor de su estabilidad y ha llegado a alcanzar velocidades de 10 ns. Se presenta en módulos DIMM de 168 contactos (64 bits). El ser una memoria de 64 bits, implica que no es necesario instalar los módulos por parejas de módulos de igual tamaño, velocidad y marca
PC-100 DRAM: Este tipo de memoria, en principio con tecnología SDRAM, aunque también la habrá EDO. La especificación para esta memoria se basa sobre todo en el uso no sólo de chips de memoria de alta calidad, sino también en circuitosimpresos de alta calidad de 6 o 8 capas, en vez de las habituales 4; en cuanto al circuito impreso este debe cumplir unas tolerancias mínimas de interferencia eléctrica; por último, los ciclos de memoria también deben cumplir unas especificaciones muy exigentes. De cara a evitar posibles confusiones, los módulos compatibles con este estándar deben estar identificados así: PC100-abc-def.
BEDO (burst Extended Data Output): Fue diseñada originalmente para soportar mayores velocidades de BUS. Al igual que la memoria SDRAM, esta memoria es capaz de transferir datos al procesador en cada ciclo de reloj, pero no de forma continuada, como la anterior, sino a ráfagas (bursts), reduciendo, aunque no suprimiendo totalmente, los tiempos de espera del procesador para escribir o leer datos de memoria.
RDRAM:(Direct Rambus DRAM). Es un tipo de memoria de 64 bits que puede producir ráfagas de 2ns y puede alcanzar tasas de transferencia de 533 MHz, con picos de 1,6 GB/s. Pronto podrá verse en el mercado y es posible que tu próximo equipo tenga instalado este tipo de memoria. Es el componente ideal para las tarjetas gráficas AGP, evitando los cuellos de botella en la transferencia entre la tarjeta gráfica y la memoria de sistema durante el acceso directo a memoria (DIME) para el almacenamiento de texturas gráficas. Hoy en día la podemos encontrar en las consolas NINTENDO 64.
DDR SDRAM: (Double Data Rate SDRAM o SDRAM-II). Funciona a velocidades de 83, 100 y 125MHz, pudiendo doblar estas velocidades en la transferencia de datos a memoria. En un futuro, esta velocidad puede incluso llegar a triplicarse o cuadriplicarse, con lo que se adaptaría a los nuevos procesadores. Este tipo de memoria tiene la ventaja de ser una extensión de la memoria SDRAM, con lo que facilita su implementación por la mayoría de los fabricantes.
SLDRAM: Funcionará a velocidades de 400MHz, alcanzando en modo doble 800MHz, con transferencias de 800MB/s, llegando a alcanzar 1,6GHz, 3,2GHz en modo doble, y hasta 4GB/s de transferencia. Se cree que puede ser la memoria a utilizar en los grandes servidores por la alta transferencia de datos.
ESDRAM: Este tipo de memoria funciona a 133MHz y alcanza transferencias de hasta 1,6 GB/s, pudiendo llegar a alcanzar en modo doble, con una velocidad de 150MHz hasta 3,2 GB/s.
La memoria FPM (Fast Page Mode) y la memoria EDO también se utilizan en tarjetas gráficas, pero existen además otros tipos de memoria DRAM, pero que SÓLO de utilizan en TARJETAS GRÁFICAS, y son los siguientes:
MDRAM (Multibank DRAM) Es increíblemente rápida, con transferencias de hasta 1 GIGA/s, pero su coste también es muy elevado.
SGRAM(Synchronous Graphic RAM) Ofrece las sorprendentes capacidades de la memoria SDRAM para las tarjetas gráficas. Es el tipo de memoria más popular en las nuevas tarjetas gráficas aceleradoras 3D.
VRAM Es como la memoria RAM normal, pero puede ser accedida al mismo tiempo por el monitor y por el procesador de la tarjeta gráfica, para suavizar la presentación gráfica en pantalla, es decir, se puede leer y escribir en ella al mismo tiempo.
WRAM (Window RAM) Permite leer y escribir información de la memoria al mismo tiempo, como en la VRAM, pero está optimizada para la presentación de un gran número de coloresy para altas resoluciones de pantalla. Es un poco más económica que la anterior.
Para procesadores lentos, por ejemplo el 486, la memoria FPM era suficiente. Con procesadores más rápidos, como los Pentium de primera generación, se utilizaban memorias EDO. Con los últimos procesadores Pentium de segunda y tercera generación, la memoria SDRAM es la mejor solución.
La memoria más exigente es la PC100 (SDRAM a 100 MHz), necesaria para montar un AMD K6-2 o un Pentium a 350 MHz o más. Va a 100 MHz en vez de los 66 MHZ usuales.
La memoria ROM se caracteriza porque solamente puede ser leída (ROM=Read Only Memory). Alberga una información esencial para el funcionamiento del computador, que por lo tanto no puede ser modificada porque ello haría imposible la continuidad de ese funcionamiento.
Uno de los elementos más característicos de la memoria ROM, es el BIOS, (Basic Input-Output System = sistema básico de entrada y salida de datos) que contiene un sistema de programas mediante el cual el computador "arranca" o "inicializa", y que están "escritos" en forma permanente en un circuito de los denominados CHIPS que forman parte de los componentes físicos del computador, llamados "hardware".
HARDWARE Y SOFTWARE Y SUS DISPOSITIVOS DE ENTRADA Y SALIDAS

Hardware
Hardware típico de una computadora personal.
1. Monitor
2. Placa base
3. CPU
4. Memoria RAM
5. Tarjeta de expansión
6. Fuente de alimentación
7. Disco óptico
8. Disco duro
9. Teclado
10. Mouse
Hardware (pronunciación AFI: /ˈhɑːdˌwɛə/ ó /ˈhɑɹdˌwɛɚ/) corresponde a todas las partes físicas y tangibles1 de una computadora: sus componentes eléctricos, electrónicos, electromecánicos y mecánicos;2 sus cables, gabinetes o cajas, periféricos de todo tipo y cualquier otro elemento físico involucrado; contrariamente al soporte lógico e intangible que es llamado software. El término proviene del inglés3 y es definido por la RAE como el "Conjunto de los componentes que integran la parte material de una computadora".4 Sin embargo, el término, aunque es lo más común, no necesariamente se aplica a una computadora tal como se la conoce, así por ejemplo, un robot también posee hardware (y software).5 6
La historia del hardware del computador se puede clasificar en tres generaciones, cada una caracterizada por un cambio tecnológico de importancia. Este hardware se puede clasificar en: básico, el estrictamente necesario para el funcionamiento normal del equipo, y el complementario, el que realiza funciones específicas.
Un sistema informático se compone de una CPU, encargada de procesar los datos, uno o varios periféricos de entrada, los que permiten el ingreso de la información y uno o varios periféricos de salida, los que posibilitan dar salida (normalmente en forma visual o auditiva) a los datos.
Historia
La clasificación evolutiva del hardware del computador electrónico, está dividida en generaciones, donde cada una supone un cambio tecnológico muy notable. El origen de las primeras es sencillo de establecer, ya que en ellas el hardware fue sufriendo cambios radicales. 7 Los componentes esenciales que constituyen la electrónica del computador fueron totalmente reemplazados en las primeras tres generaciones, originando cambios que resultaron trascendentales. En las últimas décadas es más difícil establecer las nuevas generaciones, ya que los cambios han sido graduales y existe cierta continuidad en las tecnologías usadas. En principio, se pueden distinguir:
• 1ª Generación (1945-1956): Electrónica implementada con tubos de vacío. Fueron las primeras máquinas que desplazaron los componentes electromecánicos (relés).
• 2ª Generación (1957-1963): Electrónica desarrollada con transistores. La lógica discreta era muy parecida a la anterior, pero la implementación resultó mucho más pequeña, reduciendo, entre otros factores, el tamaño de un computador en notable escala.
• 3ª Generación (1964-hoy): Electrónica basada en circuitos Integrados . Esta tecnología permitió integrar cientos de transistores y otros componentes electrónicos en un único circuito integrado conformando una pastilla de silicio. Las computadoras redujeron así considerablemente su costo y tamaño, incrementándose su capacidad, velocidad y fiabilidad, hasta producir máquinas como las que existen en la actualidad.
• 4ª Generación (futuro): Probablemente se originará cuando los circuitos de silicio, integrados a alta escala, sean reemplazados por un nuevo tipo de tecnología. 8
La aparición del microprocesador marca un hito de relevancia, y para muchos autores constituye el inicio de la cuarta generación.9 A diferencia de los cambios tecnológicos anteriores, su invención no supuso la desaparición radical de los computadores que no lo utilizaban. Así, aunque el microprocesador 4004 fue lanzado al mercado en 1971, todavía a comienzo de los 80's había computadores, como el PDP-11/44,10 con lógica carente de microprocesador que continuaban exitosamente en el mercado; es decir, en este caso el desplazamiento ha sido muy gradual.
Otro hito tecnológico usado con frecuencia para definir el inicio de la cuarta generación es la aparición de los circuitos integrados VLSI (Very Large Scale Integration), a principios de los ochenta. Al igual que el microprocesador no supuso el cambio inmediato y la rápida desaparición de los computadores basados en circuitos integrados en más bajas escalas de integración. Muchos equipos implementados con tecnologías VLSI y MSI (Medium Scale Integration) aun coexistían exitosamente hasta bien entrados los 90.
Tipos de hardware
Microcontrolador Motorola 68HC11 y chips de soporte que podrían constituir el hardware de un equipo electrónico industrial.
Una de las formas de clasificar el Hardware es en dos categorías: por un lado, el "básico", que abarca el conjunto de componentes indispensables necesarios para otorgar la funcionalidad mínima a una computadora, y por otro lado, el "Hardware complementario", que, como su nombre indica, es el utilizado para realizar funciones específicas (más allá de las básicas), no estrictamente necesarias para el funcionamiento de la computadora.
Así es que: Un medio de entrada de datos, la unidad de procesamiento y memoria y un medio de salida de datos constituye el "hardware básico".
Los medios de entrada y salida de datos estrictamente indispensables dependen de la aplicación: desde un punto de vista de un usuario común, se debería disponer, al menos, de un teclado y un monitor para entrada y salida de información, respectivamente; pero ello no implica que no pueda haber una computadora (por ejemplo controlando un proceso) en la que no sea necesario teclado ni monitor, bien puede ingresar información y sacar sus datos procesados, por ejemplo, a través de una placa de adquisición/salida de datos.
Las computadoras son aparatos electrónicos capaces de interpretar y ejecutar instrucciones programadas y almacenadas en su memoria, ellas consisten básicamente en operaciones aritmético-lógicas y de entrada/salida.11 Se reciben las entradas (datos), se las procesa y almacena (procesamiento), y finalmente se producen las salidas (resultados del procesamiento). Por ende todo sistema informático tiene, al menos, componentes y dispositivos hardware dedicados a alguna de las funciones antedichas;12 a saber:
1. Procesamiento: Unidad Central de Proceso o CPU
2. Almacenamiento: Memorias
3. Entrada: Periféricos de Entrada (E)
4. Salida: Periféricos de salida (S)
5. Entrada/Salida: Periféricos mixtos (E/S)
Desde un punto de vista básico y general, un dispositivo de entrada es el que provee el medio para permitir el ingreso de información, datos y programas (lectura); un dispositivo de salida brinda el medio para registrar la información y datos de salida (escritura); la memoria otorga la capacidad de almacenamiento, temporal o permanente (almacenamiento); y la CPU provee la capacidad de cálculo y procesamiento de la información ingresada (transformación).13
Un periférico mixto es aquél que puede cumplir funciones tanto de entrada como de salida, el ejemplo más típico es el disco rígido (ya que en él se lee y se graba información y datos).
Unidad Central de Procesamiento
Microprocesador de 64 bits doble núcleo, el AMD Athlon 64 X2 3600.
La CPU, siglas en inglés de Unidad Central de Procesamiento, es la componente fundamental del computador, encargada de interpretar y ejecutar instrucciones y de procesar datos.14 En los computadores modernos, la función de la CPU la realiza uno o más microprocesadores. Se conoce como microprocesador a un CPU que es manufacturado como un único circuito integrado.
Un servidor de red o una máquina de cálculo de alto rendimiento (supercomputación), puede tener varios, incluso miles de microprocesadores trabajando simultáneamente o en paralelo (multiprocesamiento); en este caso, todo ese conjunto conforma la CPU de la máquina.
Las unidades centrales de proceso (CPU) en la forma de un único microprocesador no sólo están presentes en las computadoras personales (PC), sino también en otros tipos de dispositivos que incorporan una cierta capacidad de proceso o "inteligencia electrónica"; como pueden ser: controladores de procesos industriales , televisores, automóviles, calculadores, aviones, teléfonos móviles, electrodomésticos, juguetes y muchos más.
Placa base formato µATX.
El microprocesador se monta en la llamada placa madre, sobre el un zócalo conocido como Socket de CPU, que permite además las conexiones eléctricas entre los circuitos de la placa y el procesador. Sobre el procesador y ajustado a la tarjeta madre se fija un disipador de calor, que por lo general es de aluminio, en algunos casos de cobre; éste es indispensable en los microprocesadores que consumen bastante energía, la cual, en gran parte, es emitida en forma de calor: En algunos casos pueden consumir tanta energía como una lámpara incandescente (de 40 a 130 vatios).
Adicionalmente, sobre el disipador se acopla un ventilador, que está destinado a forzar la circulación de aire para extraer más rápidamente el calor emitido por el disipador. Complementariamente, para evitar daños por efectos térmicos, también se suelen instalar sensores de temperatura del microprocesador y sensores de revoluciones del ventilador.
La gran mayoría de los circuitos electrónicos e integrados que componen el hardware del computador van montados en la placa madre.
La placa madre, también conocida como placa base o con el anglicismo "board",15 es un gran circuito impreso sobre el que se suelda el chipset, las ranuras de expansión (slots), los zócalos, conectores, diversos integrados, etc. Es el soporte fundamental que aloja y comunica a todos los demás componentes por medio de: Procesador, módulos de memoria RAM, tarjetas gráficas, tarjetas de expansión, periféricos de entrada y salida. Para comunicar esos componentes, la placa base posee una serie de buses con los cuales se trasmiten los datos dentro y hacia afuera del sistema.
La tendencia de integración ha hecho que la placa base se convierta en un elemento que incluye también la mayoría de las funciones básicas (vídeo, audio, red, puertos de varios tipos), funciones que antes se realizaban con tarjetas de expansión. Aunque ello no excluye la capacidad de instalar otras tarjetas adicionales específicas, tales como capturadoras de vídeo, tarjetas de adquisición de datos, etc.
Memoria RAM
Del inglés Random Access Memory, literalmente significa "memoria de acceso aleatorio". El término tiene relación con la característica de presentar iguales tiempos de acceso a cualquiera de sus posiciones (ya sea para lectura o para escritura). Esta particularidad también se conoce como "acceso directo".
La RAM es la memoria utilizada en una computadora para el almacenamiento transitorio y de trabajo (no masivo). En la RAM se almacena temporalmente la información, datos y programas que la Unidad de Procesamiento (CPU) lee, procesa y ejecuta. La memoria RAM es conocida como Memoria principal de la computadora, también como "Central o de Trabajo"; 16 a diferencia de las llamadas memorias auxiliares y de almacenamiento masivo (como discos duros, cintas magnéticas u otras memorias).
Las memorias RAM son, comúnmente, volátiles; lo cual significa que pierden rápidamente su contenido al interrumpir su alimentación eléctrica.
Las más comunes y utilizadas como memoria central son "dinámicas" (DRAM), lo cual significa que tienden a perder sus datos almacenados en breve tiempo (por descarga, aún estando con alimentación eléctrica), por ello necesitan un circuito electrónico específico que se encarga de proveerle el llamado "refresco" (de energía) para mantener su información.
La memoria RAM de un computador se provee de fábrica e instala en lo que se conoce como “módulos”. Ellos albergan varios circuitos integrados de memoria DRAM que, conjuntamente, conforman toda la memoria principal.
Módulo de memoria RAM dinámica
Es la presentación más común en computadores modernos (computador personal, servidor); son tarjetas de circuito impreso que tienen soldados circuitos integrados de memoria por una o ambas caras, además de otros elementos, tales como resistencias y capacitores. Esta tarjeta posee una serie de contactos metálicos (con un recubrimiento de oro) que permite hacer la conexión eléctrica con el bus de memoria del controlador de memoria en la placa base.
Los integrados son de tipo DRAM, memoria denominada "dinámica", en la cual las celdas de memoria son muy sencillas (un transistor y un condensador), permitiendo la fabricación de memorias con gran capacidad (algunos cientos de Megabytes) a un costo relativamente bajo. Las posiciones de memoria o celdas, están organizadas en matrices y almacenan cada una un bit. Para acceder a ellas se han ideado varios métodos y protocolos cada uno mejorado con el objetivo de acceder a las celdas requeridas de la manera más veloz posible.
Memorias RAM con tecnologías usadas en la actualidad.
Entre las tecnologías recientes para integrados de memoria DRAM usados en los módulos RAM se encuentran:
• SDR SDRAM Memoria con un ciclo sencillo de acceso por ciclo de reloj. Actualmente en desuso, fue popular en los equipos basados en el Pentium III y los primeros Pentium 4.
• DDR SDRAM Memoria con un ciclo doble y acceso anticipado a dos posiciones de memoria consecutivas. Fue popular en equipos basados en los procesadores Pentium 4 y Athlon 64.
• DDR2 SDRAM Memoria con un ciclo doble y acceso anticipado a cuatro posiciones de memoria consecutivas. Es la memoria más usada actualmente.
• DDR3 SDRAM Memoria con un ciclo doble y acceso anticipado a ocho posiciones de memoria consecutivas. Es un tipo de memoria en auge, pero por su costo sólo es utilizada en equipos de gama alta.
Los estándares JEDEC, establecen las características eléctricas y las físicas de los módulos, incluyendo las dimensiones del circuito impreso.
Los estándares usados actualmente son:
• DIMM Con presentaciones de 168 pines (usadas con SDR y otras tecnologías antiguas), 184 pines (usadas con DDR y el obsoleto SIMM) y 240 (para las tecnologías de memoria DDR2 y DDR3).
• SO-DIMM Para computadores portátiles, es una miniaturización de la versión DIMM en cada tecnología. Existen de 144 pines (usadas con SDR), 200 pines (usadas con DDR y DDR2) y 240 pines (para DDR3).
Memorias RAM especiales
Hay memorias RAM con características que las hacen particulares, y que normalmente no se utilizan como memoria central de la computadora; entre ellas se puede mencionar:
• SRAM: Siglas de Static Random Access Memory. Es un tipo de memoria más rápida que la DRAM (Dynamic RAM). El término "estática" se deriva del hecho que no necesita el refresco de sus datos. La RAM estática no necesita circuito de refresco, pero ocupa más espacio y utiliza más energía que la DRAM. Este tipo de memoria, debido a su alta velocidad, es usada como memoria caché.
• NVRAM: Siglas de Non-Volatile Random Access Memory. Memoria RAM no volátil (mantiene la información en ausencia de alimentación eléctrica). Hoy en día, la mayoría de memorias NVRAM son memorias flash, muy usadas para teléfonos móviles y reproductores portátiles de MP3.
• VRAM: Siglas de Video Random Access Memory. Es un tipo de memoria RAM que se utiliza en las tarjetas gráficas del computador. La característica particular de esta clase de memoria es que es accesible de forma simultánea por dos dispositivos. Así, es posible que la CPU grabe información en ella, al tiempo que se leen los datos que serán visualizados en el Monitor de computadora.
De las anteriores a su vez, hay otros subtipos más.
Periféricos
Artículo principal: Periféricos
Se entiende por periférico a las unidades o dispositivos que permiten a la computadora comunicarse con el exterior, esto es, tanto ingresar como exteriorizar información y datos.12 Los periféricos son los que permiten realizar las operaciones conocidas como de entrada/salida (E/S).13
Aunque son estrictamente considerados “accesorios” o no esenciales, muchos de ellos son fundamentales para el funcionamiento adecuado de la computadora moderna; por ejemplo, el teclado, el disco duro y el monitor son elementos actualmente imprescindibles; pero no lo son un scanner o un plotter. Para ilustrar este punto: en los años 80, muchas de las primeras computadoras personales no utilizaban disco duro ni mouse (o ratón), tenían sólo una o dos disqueteras, el teclado y el monitor como únicos periféricos.
Periféricos de entrada (E)
Teclado para PC inalámbrico.
Ratón (Mouse) común alámbrico.
De esta categoría son aquellos que permiten el ingreso de información, en general desde alguna fuente externa o por parte del usuario. Los dispositivos de entrada proveen el medio fundamental para transferir hacia la computadora (más propiamente al procesador) información desde alguna fuente, sea local o remota. También permiten cumplir la esencial tarea de leer y cargar en memoria el sistema operativo y las aplicaciones o programas informáticos, los que a su vez ponen operativa la computadora y hacen posible realizar las más diversas tareas.13
Entre los periféricos de entrada se puede mencionar: 12 teclado, mouse o ratón, escáner, micrófono, cámara web , lectores ópticos de código de barras, Joystick, lectora de CD o DVD (sólo lectoras), placas de adquisición/conversión de datos, etc.
Pueden considerarse como imprescindibles para el funcionamiento, al teclado, mouse y algún tipo de lectora de discos; ya que tan sólo con ellos el hardware puede ponerse operativo para un usuario. Los otros son bastante accesorios, aunque en la actualidad pueden resultar de tanta necesidad que son considerados parte esencial de todo el sistema
Impresora de inyección de tinta.
Periféricos de salida (S)
Son aquellos que permiten emitir o dar salida a la información resultante de las operaciones realizadas por la CPU (procesamiento).
Los dispositivos de salida aportan el medio fundamental para exteriorizar y comunicar la información y datos procesados; ya sea al usuario o bien a otra fuente externa, local o remota.13
Los dispositivos más comunes de este grupo son los monitores clásicos (no de pantalla táctil), las impresoras, y los altavoces. 12
Entre los periféricos de salida puede considerarse como imprescindible para el funcionamiento del sistema al monitor. Otros, aunque accesorios, son sumamente necesarios para un usuario que opere un computador moderno.
Periféricos mixtos (E/S
Piezas de un Disco rígido.
Son aquellos dispositivos que pueden operar de ambas formas: tanto de entrada como de salida.13 Típicamente, se puede mencionar como periféricos mixtos o de Entrada/Salida a: discos rígidos, disquetes, unidades de cinta magnética, lecto-grabadoras de CD/DVD, discos ZIP, etc. También entran en este rango, con sutil diferencia, otras unidades, tales como: Memoria flash, tarjetas de red, módems, placas de captura/salida de vídeo, etc. 12
Si bien se puede clasificar al pendrive (lápiz de memoria), memoria flash o memoria USB en la categoría de memorias, normalmente se los utiliza como dispositivos de almacenamiento masivo; siendo todos de categoría Entrada/Salida.17
Los dispositivos de almacenamiento masivo12 también son conocidos como "Memorias Secundarias o Auxiliares". Entre ellos, sin duda, el disco duro ocupa un lugar especial, ya que es el de mayor importancia en la actualidad, en él se aloja el sistema operativo, todas las aplicaciones, utilitarios, etc. que utiliza el usuario; además de tener la suficiente capacidad para albergar información y datos en grandes volúmenes por tiempo prácticamente indefinido. Los servidores Web, de correo electrónico y de redes con bases de datos, utilizan discos rígidos de grandes capacidades y con una tecnología que les permite trabajar a altas velocidades.
La pantalla táctil (no el monitor clásico) es un dispositivo que se considera mixto, ya que además de mostrar información y datos (salida) puede actuar como un dispositivo de entrada, reemplazando, por ejemplo, a algunas funciones del ratón y/o del teclado.
Hardware gráfico
GPU de Nvidia GeForce.
El hardware gráfico lo constituyen básicamente las tarjetas de video.Actualmente poseen su propia memoria y unidad de procesamiento, esta última llamada unidad de procesamiento gráfico (o GPU, siglas en inglés de Graphics Processing Unit). El objetivo básico de la GPU es realizar exclusivamente procesamiento gráfico, 18 liberando al procesador principal (CPU) de esa costosa tarea (en tiempo) para que pueda así efectuar otras funciones más eficientemente. Antes de esas tarjetas de video con aceleradores, era el procesador principal el encargado de construir la imagen mientras la sección de video (sea tarjeta o de la placa base) era simplemente un traductor de las señales binarias a las señales requeridas por el monitor; y buena parte de la memoria principal (RAM) de la computadora también era utilizada para estos fines.
La Ley de Moore establece que cada 18 a 24 meses la cantidad de transistores que puede contener un circuito integrado se logra duplicar; en el caso de los GPU esta tendencia es bastante más notable, duplicando o aún más de lo indicado en la ley de Moore.19
Desde la década de 1990, la evolución en el procesamiento gráfico ha tenido un crecimiento vertiginoso; las actuales animaciones por computadoras y videojuegos eran impensables veinte años atrás
Software
De Wikipedia, la enciclopedia libre
Saltar a navegación, búsqueda
Uno o varios wikipedistas están trabajando actualmente en extender este artículo o sección.
Es posible que, a causa de ello, haya lagunas de contenido o deficiencias de formato. Es posible ayudar y editar pero, por favor, antes de realizar correcciones mayores, contacta con ellos en su página de usuario o en la página de discusión del artículo para poder coordinar la redacción.
Software[1] (pronunciación AFI:[ˈsɔft.wɛɻ]), palabra proveniente del inglés (literalmente: partes blandas o suaves), que en español no posee una traducción adecuada al contexto, por lo cual se la utiliza asiduamente sin traducir y así fue admitida por la Real Academia Española (RAE). Aunque no es estrictamente lo mismo, suele sustituirse por expresiones tales como programas (informáticos) o aplicaciones (informáticas).[2]
La palabra «software» se refiere al equipamiento lógico o soporte lógico de una computadora digital, y comprende el conjunto de los componentes lógicos necesarios para hacer posible la realización de una tarea específica, en contraposición a los componentes físicos del sistema (hardware).
Fig. 1 - Muestra de interfaces y ventanas de Programas en una pantalla.Tales componentes lógicos incluyen, entre otros, aplicaciones informáticas tales como procesador de textos, que permite al usuario realizar todas las tareas concernientes a edición de textos; software de sistema, tal como un sistema operativo, el que, básicamente, permite al resto de los programas funcionar adecuadamente, facilitando la interacción con los componentes físicos y el resto de las aplicaciones, también provee una interfaz para el usuario.
En la figura 1 se muestra uno o más software en ejecución, en este caso con ventanas, iconos y menúes que componen las interfaces gráficas, que comunican la computadora con el usuario, y le permiten interactuar.
Software es lo que se denomina producto en Ingeniería de Software.[3]
Contenido [ocultar]
1 Definición de software
2 Clasificación del software
3 Proceso de creación del software
3.1 Modelos de proceso o ciclo de vida
3.1.1 Modelo cascada
3.1.2 Modelos evolutivos
3.1.2.1 Modelo iterativo incremental
3.1.2.2 Modelo espiral
3.1.2.3 Modelo espiral Win & Win
4 Etapas en el desarrollo del software
4.1 Captura, análisis y especificación de requisitos
4.1.1 Procesos, modelado y formas de elicitación de requisitos
4.1.2 Clasificación e identificación de requerimientos
4.2 Diseño del sistema
4.3 Codificación del software
4.4 Pruebas (unitarias y de integración)
4.5 Instalación y paso a producción
4.6 Mantenimiento
5 Véase también
5.1 Modelos de ciclo de vida
6 Referencias
7 Bibliografía
7.1 Libros
7.2 Artículos y revistas
8 Enlaces externos
Definición de software
Probablemente la definición más formal de software sea la siguiente:
Es el conjunto de los programas de cómputo, procedimientos, reglas, documentación y datos asociados que forman parte de las operaciones de un sistema de computación.
Extraído del estándar 729 del IEEE[4]
Considerando esta definición, el concepto de software va más allá de los programas de cómputo en sus distintos estados: código fuente, binario o ejecutable; también su documentación, datos a procesar e información de usuario forman parte del software: es decir, abarca todo lo intangible, todo lo "no físico" relacionado.
El término «software» fue usado por primera vez en este sentido por John W. Tukey en 1957. En las ciencias de la computación y la ingeniería de software, el software es toda la información procesada por los sistemas informáticos: programas y datos. El concepto de leer diferentes secuencias de instrucciones desde la memoria de un dispositivo para controlar los cálculos fue introducido por Charles Babbage como parte de su máquina diferencial. La teoría que forma la base de la mayor parte del software moderno fue propuesta por vez primera por Alan Turing en su ensayo de 1936, "Los números computables", con una aplicación al problema de decisión.
Clasificación del software
Si bien esta distinción es, en cierto modo, arbitraria, y a veces confusa, a los fines prácticos se puede clasificar al software en tres grandes tipos:
Software de sistema: Su objetivo es desvincular adecuadamente al usuario y al programador de los detalles de la computadora en particular que se use, aislándolo especialmente del procesamiento referido a las características internas de: memoria, discos, puertos y dispositivos de comunicaciones, impresoras, pantallas, teclados, etc. El software de sistema le procura al usuario y programador adecuadas interfaces de alto nivel, herramientas y utilidades de apoyo que permiten su mantenimiento. Incluye entre otros:
Sistemas operativos
Controladores de dispositivos
Herramientas de diagnóstico
Herramientas de Corrección y Optimización
Servidores
Utilidades
Software de programación: Es el conjunto de herramientas que permiten al programador desarrollar programas informáticos, usando diferentes alternativas y lenguajes de programación, de una manera práctica. Incluye entre otros:
Editores de texto
Compiladores
Intérpretes
Enlazadores
Depuradores
Entornos de Desarrollo Integrados (IDE): Agrupan las anteriores herramientas, usualmente en un entorno visual, de forma tal que el programador no necesite introducir múltiples comandos para compilar, interpretar, depurar, etc. Habitualmente cuentan con una avanzada interfaz gráfica de usuario (GUI).
Software de aplicación: Es aquel que permite a los usuarios llevar a cabo una o varias tareas específicas, en cualquier campo de actividad susceptible de ser automatizado o asistido, con especial énfasis en los negocios. Incluye entre otros:
Aplicaciones para Control de sistemas y automatización industrial
Aplicaciones ofimáticas
Software educativo
Software empresarial
Bases de datos
Telecomunicaciones (p.ej. internet y toda su estructura lógica)
Videojuegos
Software médico
Software de Cálculo Numérico y simbólico.
Software de Diseño Asistido (CAD)
Software de Control Numérico (CAM)
Proceso de creación del software
Se define como Proceso al conjunto ordenado de pasos a seguir para llegar a la solución de un problema u obtención de un producto, en este caso particular, para lograr la obtención de un producto software que resuelva un problema.
El proceso de creación de software puede llegar a ser muy complejo, dependiendo de su porte, características y criticidad del mismo. Por ejemplo la creación de un sistema operativo es una tarea que requiere proyecto, gestión, numerosos recursos y todo un equipo disciplinado de trabajo. En el otro extremo, si se trata de un sencillo programa (por ejemplo, la resolución de una ecuación de segundo orden), éste puede ser realizado por un solo programador (incluso aficionado) fácilmente. Es así que normalmente se dividen en tres categorías según su tamaño (líneas de código) y/o costo: de Pequeño, Mediano y Gran porte. Existen varias metodologías para estimarlo, una de las más populares es el sistema COCOMO que provee métodos y un software (programa) que calcula y provee una estimación de todos los costos de producción en un "proyecto software" (relación horas/hombre, costo monetario, cantidad de líneas fuente de acuerdo a lenguaje usado, etc.).
Considerando los de gran porte, es necesario realizar tantas y tan complejas tareas, tanto técnicas, de gerenciamiento, fuerte gestión y análisis diversos (entre otras) que toda una ingeniería hace falta para su estudio y realización: es la Ingeniería de Software.
En tanto que en los de mediano porte, pequeños equipos de trabajo (incluso un avezado analista-programador solitario) pueden realizar la tarea. Aunque, siempre en casos de mediano y gran porte (y a veces también en algunos de pequeño porte, según su complejidad), se deben seguir ciertas etapas que son necesarias para la construcción del software. Tales etapas, si bien deben existir, son flexibles en su forma de aplicación, de acuerdo a la metodología o Proceso de Desarrollo escogido y utilizado por el equipo de desarrollo o por el analista-programador solitario (si fuere el caso).
Los "procesos de desarrollo de software" poseen reglas preestablecidas, y deben ser aplicados en la creación del software de mediano y gran porte, ya que en caso contrario lo más seguro es que el proyecto o no logre concluir o termine sin cumplir los objetivos previstos, y con variedad de fallos inaceptables (fracasan, en pocas palabras). Entre tales "procesos" los hay ágiles o livianos (ejemplo XP), pesados y lentos (ejemplo RUP) y variantes intermedias; y normalmente se aplican de acuerdo al tipo, porte y tipología del software a desarrollar, a criterio del líder (si lo hay) del equipo de desarrollo. Algunos de esos procesos son Extreme Programming (XP), Rational Unified Process (RUP), Feature Driven Development (FDD), etc.
Cualquiera sea el "proceso" utilizado y aplicado al desarrollo del software (RUP, FDD, etc), y casi independientemente de él, siempre se debe aplicar un "Modelo de Ciclo de Vida".[5]
Se estima que, del total de proyectos software grandes emprendidos, un 28% fracasan, un 46% caen en severas modificaciones que lo retrasan y un 26% son totalmente exitosos. [6]
Cuando un proyecto fracasa, rara vez es debido a fallas técnicas, la principal causa de fallos y fracasos es la falta de aplicación de una buena metodología o proceso de desarrollo. Entre otras, una fuerte tendencia, desde hace pocas décadas, es mejorar las metodologías o procesos de desarrollo, o crear nuevas y concientizar a los profesionales en su utilización adecuada. Normalmente los especialistas en el estudio y desarrollo de estas áreas (metodologías) y afines (tales como modelos y hasta la gestión misma de los proyectos) son los Ingenieros en Software, es su orientación. Los especialistas en cualquier otra área de desarrollo informático (analista, programador, Lic. en Informática, Ingeniero en Informática, Ingeniero de Sistemas, etc.) normalmente aplican sus conocimientos especializados pero utilizando modelos, paradigmas y procesos ya elaborados.
Es común para el desarrollo de software de mediano porte que los equipos humanos involucrados apliquen sus propias metodologías, normalmente un híbrido de los procesos anteriores y a veces con criterios propios.
El proceso de desarrollo puede involucrar numerosas y variadas tareas[5] , desde lo administrativo, pasando por lo técnico y hasta la gestión y el gerenciamiento. Pero casi rigurosamente siempre se cumplen ciertas etapas mínimas; las que se pueden resumir como sigue:
Captura, Elicitación[7] , Especificación y Análisis de requisitos (ERS)
Diseño
Codificación
Pruebas (unitarias y de integración)
Instalación y paso a Producción
Mantenimiento
En las anteriores etapas pueden variar ligeramente sus nombres, o ser más globales, o contrariamente, ser más refinadas; por ejemplo indicar como una única fase (a los fines documentales e interpretativos) de "Análisis y Diseño"; o indicar como "Implementación" lo que está dicho como "Codificación"; pero en rigor, todas existen e incluyen, básicamente,las mismas tareas específicas.
En el apartado 4 del presente artículo se brindan mayores detalles de cada una de las listadas etapas.
Modelos de proceso o ciclo de vida
Para cada una las fases o etapas listadas en el ítem anterior, existen sub-etapas (o tareas). El modelo de proceso o modelo de ciclo de vida utilizado para el desarrollo define el orden para las tareas o actividades involucradas[5] también definen la coordinación entre ellas, enlace y realimentación entre las mencionadas etapas. Entre los más conocidos se puede mencionar: modelo en cascada o secuencial, modelo espiral, modelo iterativo incremental. De los antedichos hay a su vez algunas variantes o alternativas, más o menos atractivas según sea la aplicación requerida y sus requisitos.[6]
Modelo cascada
Este, aunque es más comúnmente conocido como modelo en cascada es también llamado "modelo clásico", "modelo tradicional" o "modelo lineal secuencial".
El modelo en cascada puro difícilmente se utilice tal cual, pues esto implicaría un previo y absoluto conocimiento de los requisitos, la no volatilidad de los mismos (o rigidez) y etapas subsiguientes libres de errores; ello sólo podría ser aplicable a escasos y pequeños desarrollos de sistemas. En estas circunstancias, el paso de una etapa a otra de las mencionadas sería sin retorno, por ejemplo pasar del Diseño a la Codificación implicaría un diseño exacto y sin errores ni probable modificación o evolución: "codifique lo diseñado que no habrán en absoluto variantes ni errores". Esto es utópico; ya que intrínsecamente el software es de carácter evolutivo, cambiante y difícilmente libre de errores, tanto durante su desarrollo como durante su vida operativa.[5]
Fig. 2 - Modelo cascada puro o secuencial para el ciclo de vida del software.Algún cambio durante la ejecución de una cualquiera de las etapas en este modelo secuencial implicaría reiniciar desde el principio todo el ciclo completo, lo cual redundaría en altos costos de tiempo y desarrollo. La figura 2 muestra un posible esquema de el modelo en cuestión.[5]
Sin embargo, el modelo cascada en algunas de sus variantes es uno de los actualmente más utilizados[8] , por su eficacia y simplicidad, más que nada en software de pequeño y algunos de mediano porte; pero nunca (o muy rara vez) se lo usa en su forma pura, como se dijo anteriormente. En lugar de ello, siempre se produce alguna realimentación entre etapas, que no es completamente predecible ni rígida; esto da oportunidad al desarrollo de productos software en los cuales hay ciertas incertezas, cambios o evoluciones durante el ciclo de vida. Así por ejemplo, una vez capturados (elicitados) y especificados los requisitos (primera etapa) se puede pasar al diseño del sistema, pero durante esta última fase lo más probable es que se deban realizar ajustes en los requisitos (aunque sean mínimos), ya sea por fallas detectadas, ambigüedades o bien por que los propios requisitos han cambiado o evolucionado; con lo cual se debe retornar a la primera o previa etapa, hacer los pertinentes reajustes y luego continuar nuevamente con el diseño; esto último se conoce como realimentación. Lo normal en el modelo cascada será entonces la aplicación del mismo con sus etapas realimentadas de alguna forma, permitiendo retroceder de una a la anterior (e incluso poder saltar a varias anteriores) si es requerido.
De esta manera se obtiene un "modelo cascada realimentado", que puede ser esquematizado como lo ilustra la figura 3.
Fig. 3 - Modelo cascada realimentado para el ciclo de vida.Lo dicho es, a grandes rasgos, la forma y utilización de este modelo, uno de los más usados y populares.[5] El modelo Cascada Realimentado resulta muy atractivo, hasta ideal, si el proyecto presenta alta rigidéz (pocos o ningún cambio, no evolutivo), los requisitos son muy claros y están correctamente especificados.[8]
Hay más variantes similares al modelo: refino de etapas (más estapas, menores y más específicas) o incluso mostrar menos etapas de las indicadas, aunque en tal caso la faltante estará dentro de alguna otra. El orden de esas fases indicadas en el ítem previo es el lógico y adecuado, pero adviértase, como se dijo, que normalmente habrá realimentación hacia atrás.
El modelo lineal o en Cascada es el paradigma más antiguo y extensamente utilizado, sin embargo las críticas a él (ver desventajas) han puesto en duda su eficacia. Pese a todo tiene un lugar muy importante en la Ingeniería de software y continúa siendo el más utilizado; y siempre es mejor que un enfoque al azar.[8]
Desventajas del modelo cascada:[5]
Los cambios introducidos durante el desarrollo pueden confundir al equipo profesional en las etapas tempranas del proyecto. Si los cambios se producen en etapa madura (codificación o prueba) pueden ser catastróficos para un proyecto grande.
No es frecuente que el cliente o usuario final explicite clara y completamente los requisitos (etapa de inicio); y el modelo lineal lo requiere. La incertidumbre natural en los comienzos es luego difícil de acomodar.[8]
El cliente debe tener paciencia ya que el software no estará disponible hasta muy avanzado el proyecto. Un error detectado por el cliente (en fase de operación) puede ser desastroso, implicando reinicio del proyecto, con altos costos.
Modelos evolutivos
El software evoluciona con el tiempo. Los requisitos del usuario y del producto suelen cambiar conforme se desarrolla el mismo. Las fechas de mercado y la competencia hacen que no sea posible esperar a poner en el mercado un producto absolutamente completo, por lo que se debe introducir una versión funcional limitada de alguna forma para aliviar las presiones competitivas.
En esas u otras situaciones similares los desarrolladores necesitan modelos de progreso que estén diseñados para acomodarse a una evolución temporal o progresiva, donde los requisitos centrales son conocidos de antemano, aunque no estén bien definidos a nivel detalle.
En el modelo Cascada y Cascada Realimentado no se tiene en cuenta la naturaleza evolutiva del software, se plantea como estático con requisitos bien conocidos y definidos desde el inicio.[5]
Los evolutivos son modelos iterativos, permiten desarrollar versiones cada vez más completas y complejas, hasta llegar al objetivo final deseado; incluso evolucionar más allá, durante la fase de operación.
Los modelos “Iterativo Incremental” y “Espiral” (entre otros) son dos de los más conocidos y utilizados del tipo evolutivo.[8]
Modelo iterativo incremental
En términos generales, podemos distinguir, en la figura 4, los pasos generales que sigue el proceso de desarrollo de un producto software. En el modelo de ciclo de vida seleccionado, se identifican claramente dichos pasos. La Descripción del Sistema es esencial para especificar y confeccionar los distintos incrementos hasta llegar al Producto global y final. Las actividades concurrentes (Especificación, Desarrollo y Validación) sintetizan el desarrollo pormenorizado de los incrementos, que se hará posteriormente.
Fig. 4 - Diagrama genérico del desarrollo evolutivo incremental.El diagrama 4 nos muestra en forma muy esquemática, el funcionamiento de un ciclo iterativo incremental, el cual permite la entrega de versiones parciales a medida que se va construyendo el producto final.[5] Es decir, a medida que cada incremento definido llega a su etapa de operación y mantenimiento. Cada versión emitida incorpora a los anteriores incrementos las funcionalidades y requisitos que fueron analizados como necesarios.
El incremental es un modelo de tipo evolutivo que está basado en varios ciclos Cascada realimentados aplicados repetidamente, con una filosofía iterativa.[8] En la figura 5 se muestra un refino del diagrama previo, bajo un esquema temporal, para obtener finalmente el esquema del Modelo de ciclo de vida Iterativo Incremental, con sus actividades genéricas asociadas. Aquí se observa claramente cada ciclo cascada que es aplicado para la obtención de un incremento; estos últimos se van integrando para obtener el producto final completo. Cada incremento es un ciclo Cascada Realimentado, aunque, por simplicidad, en la figura 5 se muestra como secuencial puro.
Fig. 5 - Modelo iterativo incremental para el ciclo de vida del software,Se observa que existen actividades de desarrollo (para cada incremento) que son realizadas en paralelo o concurrentemente, así por ejemplo, en la figura, mientras se realiza el diseño detalle del primer incremento ya se está realizando en análisis del segundo. La figura 5 es sólo esquemática, un incremento no necesariamente se iniciará durante la fase de diseño del anterior, puede ser posterior (incluso antes), en cualquier tiempo de la etapa previa. Cada incremento concluye con la actividad de “Operación y Mantenimiento” (indicada "Operación" en la figura), que es donde se produce la entrega del producto parcial al cliente. El momento de inicio de cada incremento es dependiente de varios factores: tipo de sistema; independencia o dependencia entre incrementos (dos de ellos totalmente independientes pueden ser fácilmente iniciados al mismo tiempo si se dispone de personal suficiente); capacidad y cantidad de profesionales involucrados en el desarrollo; etc.
Bajo este modelo se entrega software “por partes funcionales más pequeñas”, pero reutilizables, llamadas incrementos. En general cada incremento se construye sobre aquel que ya fue entregado.[5]
Como se muestra en la figura 5, se aplican secuencias Cascada en forma escalonada, mientras progresa el tiempo calendario. Cada secuencia lineal o Cascada produce un incremento y a menudo el primer incremento es un sistema básico, con muchas funciones suplementarias (conocidas o no) sin entregar.
El cliente utiliza inicialmente ese sistema básico intertanto, el resultado de su uso y evaluación puede aportar al plan para el desarrollo del/los siguientes incrementos (o versiones). Además también aportan a ese plan otros factores, como lo es la priorización (mayor o menor urgencia en la necesidad de cada incremento) y la dependencia entre incrementos (o independencia).
Luego de cada integración se entrega un producto con mayor funcionalidad que el previo. El proceso se repite hasta alcanzar el software final completo.
Siendo iterativo, con el modelo incremental se entrega un producto parcial pero completamente operacional en cada incremento, y no una parte que sea usada para reajustar los requerimientos (como si ocurre en el modelo de construcción de prototipos).[8]
El enfoque incremental resulta muy útil con baja dotación de personal para el desarrollo; también si no hay disponible fecha límite del proyecto por lo que se entregan versiones incompletas pero que proporcionan al usuario funcionalidad básica (y cada vez mayor). También es un modelo útil a los fines de evaluación.
Nota: Puede ser considerado y útil, en cualquier momento o incremento incorporar temporalmente el paradigma MCP como complemento, teniendo así una mixtura de modelos que mejoran el esquema y desarrollo general.
Ejemplo:
Un procesador de texto que sea desarrollado bajo el paradigma Incremental podría aportar, en principio, funciones básicas de edición de archivos y producción de documentos (algo como un editor simple). En un segundo incremento se le podría agregar edición más sofisticada, y de generación y mezcla de documentos. En un tercer incremento podría considerarse el agregado de funciones de corrección ortográfica, esquemas de paginado y plantillas; en un cuarto capacidades de dibujo propias y ecuaciones matemáticas. Así sucesivamente hasta llegar al procesador final requerido. Así, el producto va creciendo, acercándose a su meta final, pero desde la entrega del primer incremento ya es útil y funcional para el cliente, el cual observa una respuesta rápida en cuanto a entrega temprana; sin notar que la fecha límite del proyecto puede no estar acotada ni tan definida, lo que da margen de operación y alivia presiones al equipo de desarrollo.
Como se dijo, el Iterativo Incremental es un modelo del tipo evolutivo, es decir donde se permiten y esperan probables cambios en los requisitos en tiempo de desarrollo; se admite cierto margen para que el software pueda evolucionar. Aplicable cuando los requisitos son medianamente bien conocidos pero no son completamente estáticos y definidos, cuestión esa que si es indispensable para poder utilizar un modelo Cascada.
El modelo es aconsejable para el desarrollo de software en el cual se observe, en su etapa inicial de análisis, que posee áreas bastante bien definidas a cubrir, con suficiente independencia como para ser desarrolladas en etapas sucesivas. Tales áreas a cubrir suelen tener distintos grados de apremio por lo cual las mismas se deben priorizar en un análisis previo, es decir, definir cual será la primera, la segunda, y así sucesivamente; esto se conoce como “definición de los incrementos” en base a priorización. Pueden no existir prioridades funcionales por parte del cliente, pero el desarrollador debe fijarlas de todos modos y con algún criterio, ya que en base a ellas se desarrollarán y entregarán los distintos incrementos.
El hecho de que existan incrementos funcionales del software lleva inmediatamente a pensar en un esquema de desarrollo modular, por tanto este modelo facilita tal paradigma de diseño.
En resumen, un modelo incremental lleva a pensar en un desarrollo modular, con entregas parciales del producto software denominados “incrementos” del sistema, que son escogidos en base a prioridades predefinidas de algún modo. El modelo permite una implementación con refinamientos sucesivos (ampliación y/o mejora). Con cada incremento se agrega nueva funcionalidad o se cubren nuevos requisitos o bien se mejora la versión previamente implementada del producto software.
Este modelo brinda cierta flexibilidad para que durante el desarrollo se incluyan cambios en los requisitos por parte del usuario, un cambio de requisitos propuesto y aprobado puede analizarse e implementarse como un nuevo incremento o, eventualmente, podrá constituir una mejora/adecuación de uno ya planeado. Aunque si se produce un cambio de requisitos por parte del cliente que afecte incrementos previos ya terminados (detección/incorporación tardía) se debe evaluar la factibilidad y realizar un acuerdo con el cliente, ya que puede impactar fuertemente en los costos.
La selección de este modelo permite realizar entregas funcionales tempranas al cliente (lo cual es beneficioso tanto para él como para el grupo de desarrollo). Se priorizan las entregas de aquellos módulos o incrementos en que surja la necesidad operativa de hacerlo, por ejemplo para cargas previas de información, indispensable para los incrementos siguientes.[8]
El modelo iterativo incremental no obliga a especificar con precisión y detalle absolutamente todo lo que el sistema debe hacer, (y cómo), antes de ser construido (como el caso del cascada, con requisitos congelados). Sólo se hace en el incremento en desarrollo. Esto torna más manejable el proceso y reduce el impacto en los costos. Esto es así, porque en caso de alterar o rehacer los requisitos, solo afecta una parte del sistema. Aunque, lógicamente, esta situación se agrava si se presenta en estado avanzado, es decir en los últimos incrementos. En definitiva, el modelo facilita la incorporación de nuevos requisitos durante el desarrollo.
Con un paradigma incremental se reduce el tiempo de desarrollo inicial, ya que se implementa funcionalidad parcial. También provee un impacto ventajoso frente al cliente, que es la entrega temprana de partes operativas del software.
El modelo proporciona todas las ventajas del modelo en cascada realimentado, reduciendo sus desventajas sólo al ámbito de cada incremento.
El modelo incremental no es recomendable para casos de sistemas de tiempo real, de alto nivel de seguridad, de procesamiento distribuido, y/o de alto índice de riesgos.
Modelo espiral
El modelo espiral fue propuesto inicialmente por Barry Boehm. Es un modelo evolutivo que conjuga la naturaleza iterativa del modelo MCP con los aspectos controlados y sistemáticos del Modelo Cascada. Proporciona potencial para desarrollo rápido de versiones incrementales. En el modelo Espiral el software se construye en una serie de versiones incrementales. En las primeras iteraciones la versión incremental podría ser un modelo en papel o bien un prototipo. En las últimas iteraciones se producen versiones cada vez más completas del sistema diseñado.[5] [8]
El modelo se divide en un número de Actividades de marco de trabajo, llamadas "regiones de tareas". En general existen entre tres y seis regiones de tareas (hay variantes del modelo). En la figura 6 se muestra el esquema de un Modelo Espiral con 6 regiones. En este caso se explica una variante del modelo original de Boehm, expuesto en su tratado de 1988; en 1998 expuso un tratado más reciente.
Fig. 6 - Modelo espiral para el ciclo de vida del software.Las regiones definidas en el modelo de la figura son:
Región 1 - Tareas requeridas para establecer la comunicación entre el cliente y el desarrollador.
Región 2 - Tareas inherentes a la definición de los recursos, tiempo y otra información relacionada con el proyecto.
Región 3 - Tareas necesarias para evaluar los riesgos técnicos y de gestión del proyecto.
Región 4 - Tareas para construir una o más representaciones de la aplicación software.
Región 5 - Tareas para construir la aplicación, instalarla, probarla y proporcionar soporte al usuario o cliente (Ej. documentación y práctica).
Región 6 - Tareas para obtener la reacción del cliente, según la evaluación de lo creado e instalado en los ciclos anteriores.
Las actividades enunciadas para el marco de trabajo son generales y se aplican a cualquier proyecto, grande, mediano o pequeño, complejo o no. Las regiones que definen esas actividades comprenden un "conjunto de tareas" del trabajo: ese conjunto sí se debe adaptar a las características del proyecto en particular a emprender. Nótese que lo listado en los ítems de 1 a 6 son conjuntos de tareas, algunas de las ellas normalmente dependen del proyecto o desarrollo en si.
Proyectos pequeños requieren baja cantidad de tareas y también de formalidad. En proyectos mayores o críticos cada región de tareas contiene labores de más alto nivel de formalidad. En cualquier caso se aplican actividades de protección (por ejemplo, gestión de configuración del software, garantía de calidad, etc.).
Al inicio del ciclo, o proceso evolutivo, el equipo de ingeniería gira alrededor del espiral (metafóricamente hablando) comenzando por el centro (marcado con ๑ en la figura 6) y en el sentido indicado; el primer circuito de la espiral puede producir el desarrollo de una especificación del producto; los pasos siguientes podrían generar un prototipo y progresivamente versiones más sofisticadas del software.
Cada paso por la región de planificación provoca ajustes en el plan del proyecto; el coste y planificación se realimentan en función de la evaluación del cliente. El gestor de proyectos debe ajustar el número de iteraciones requeridas para completar el desarrollo.
El modelo espiral puede ir adaptándose y aplicarse a lo largo de todo el ciclo de vida del software (en el modelo clásico, o cascada, el proceso termina a la entrega del software).
Una visión alternativa del modelo puede observarse examinando el "eje de punto de entrada de proyectos". Cada uno de los circulitos (๏) fijados a lo largo del eje representan puntos de arranque de los distintos proyectos (relacionados); a saber:
Un proyecto de "Desarrollo de Conceptos" comienza al inicio de la espiral, hace múltiples iteraciones hasta que se completa, es la zona marcada con verde.
Si lo anterior se va a desarrollar como producto real, se incia otro proyecto: "Desarrollo de nuevo Producto". Que evolucionará con iteraciones hasta culminar; es la zona marcada en color azul.
Eventual y análogamente se generarán proyectos de "Mejoras de Productos" y de "Mantenimiento de productos", con las iteraciones necesarias en cada área (zonas roja y gris, respectivamente).
Cuando la espiral se caracteriza de esta forma, está operativa hasta que el software se retira, eventualmente puede estar inactiva (el proceso), pero cuando se produce un cambio el proceso arranca nuevamente en el punto de entrada apropiado (por ejemplo, en "Mejora del Producto").
El modelo espiral da un enfoque realista, que evoluciona igual que el software; se adapta muy bien para desarrollos a gran escala.
El Espiral utiliza el MCP para reducir riesgos y permite aplicarlo en cualquier etapa de la evolución. Mantiene el enfoque clásico (cascada) pero incorpora un marco de trabajo iterativo que refleja mejor la realidad.
Este modelo requiere considerar riesgos técnicos en todas las etapas del proyecto; aplicado adecuadamente debe reducirlos antes de que sean un verdadero problema.
El Modelo evolutivo como el Espiral es particularmente apto para el desarrollo de Sistemas Operativos (complejos); también en sistemas de altos riesgos o críticos (Ej. navegadores y controladores aeronáuticos) y en todos aquellos en que sea necesaria una fuerte gestión del proyecto y sus riesgos, técnicos o de gestión.
Desventajas importantes:
Requiere mucha experiencia y habilidad para la evaluación de los riesgos, lo cual es requisito para el éxito del proyecto.
Es difícil convencer a los grandes clientes que se podrá controlar este enfoque evolutivo.
Este modelo no se ha usado tanto, como el Cascada (Incremental) o MCP, por lo que no se tiene bien medida su eficacia, es un paradigma relativamente nuevo y difícil de implementar y controlar.
Modelo espiral Win & Win
Una variante interesante del Modelo Espiral previamente visto (Fig. 6) es el "Modelo espiral Win-Win"[6] (Barry Boehm). El Modelo Espiral previo (clásico) sugiere la comunicación con el cliente para fijar los requisitos, en que simplemente se pregunta al cliente qué necesita y él proporciona la información para continuar; pero esto es en un contexto ideal que rara vez ocurre. Normalmente cliente y desarrollador entran en una negociación, se negocia coste frente a funcionalidad, rendimiento, calidad, etc.
"Es así que la obtención de requisitos requiere una negociación, que tiene éxito cuando ambas partes ganan".
Las mejores negociaciones se fuerzan en obtener "Victoria & Victoria" (Win & Win), es decir que el cliente gane obteniendo el producto que lo satisfaga, y el desarrollador también gane consiguiendo presupuesto y fecha de entrega realista. Evidentemente, este modelo requiere fuertes habilidades de negociación.
El modelo Win-Win define un conjunto de actividades de negociación al principio de cada paso alrededor de la espiral; se definen las siguientes actividades:
Identificación del sistema o subsistemas clave de los directivos(*) (saber qué quieren).
Determinación de "condiciones de victoria" de los directivos (saber qué necesitan y los satisface)
Negociación de las condiciones "victoria" de los directivos para obtener condiciones "Victoria & Victoria" (negociar para que ambos ganen).
(*) Directivo: Cliente escogido con interés directo en el producto, que puede ser premiado por la organización si tiene éxito o criticado si no.
El modelo Win & Win hace énfasis en la negociación inicial, también introduce 3 hitos en el proceso llamados "puntos de fijación", que ayudan a establecer la completitud de un ciclo de la espiral, y proporcionan hitos de decisión antes de continuar el proyecto de desarrollo del software.
Suscribirse a:
Comentarios (Atom)

